UE PRIP |
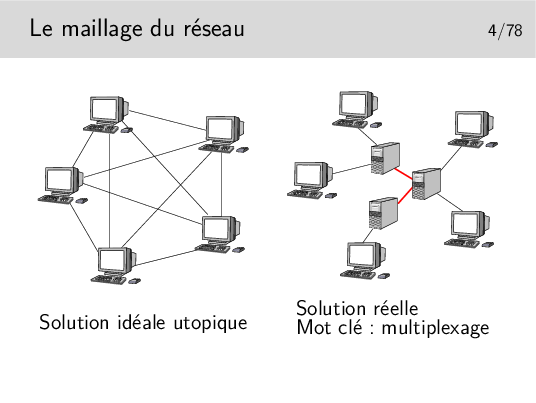
Les terminaux ne peuvent pas être tous interconnectés. Cette solution serait trop coûteuse en nombre de liaisons et ces dernières seraient la plupart du temps sous utilisées.
Les terminaux sont reliés à des machines intermédiaires, des relais, qui concentrent le trafic et acheminent les divers flux d’information sur des supports qui les relient.
Les divers flux de trafic sont acheminés sur les liens inter-noeuds de manière simultanée ou quasi simultanée. On dit qu’ils sont multiplexés et les liens entre les noeuds sont appelés de multiplex. Une des fonction des noeuds est d’assurer le multiplexage des informations sur les liens.
Un multiplex est donc une voie de communication sur laquelle on véhicule plusieurs «communications» à la fois. (Notez les guillemets, il reste à définir ce qu’est une «communication», ce n’est pas si simple)

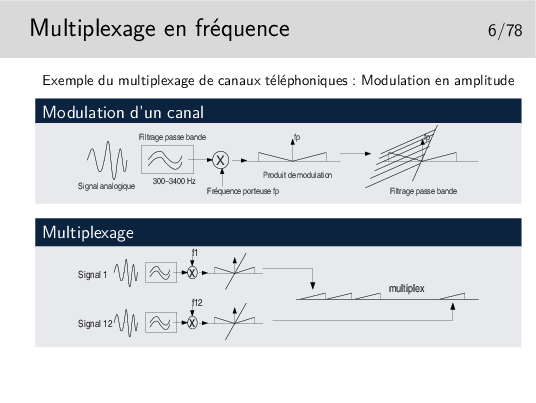
Cas du mutilpexage de canaux téléphoniques:
Le multiplexage sur fibre optique est réalisé de manière similaire. Des communications différentes peuvent être transportées par une même liaison optique, mais sur des longueurs d’onde (couleurs) différentes: c’est le multiplexage en longueur d’onde ou WDM (Wavelength-Division Multiplexing).

Chaque signal est échantillonné un certain nombre de fois par secondes, chacun avec un décalage dans le temps par rapport aux autres de telle manière qu’ils peuvent être véhiculés sur le même support sans se mélanger après multipexage.
La fréquence d’échantillonnage est telle que le signal doit pouvoir etre reconstitué sans déformations majeures. Shannon a montré que la fréquence d’échantillonnage devait être être le double de la fréquence maximum du signal à échantillonner. Ainsi, en téléphonie, la bande de fréquence est de 300-3400 Hz, on prend 0-4000 Hz par excès, donc la fréquence d’échantillonnage doit être de 8000 Hz.
Le multiplexage par échantillonnage analogique seul ne permet pas de bonnes performances. Le mutiplex ne doit pas être très long, quelques dizaines de centimètres par exemple dans un tout petit autocommutateur téléphonique. Si le support est plus long les échantillons se détériorent à cause des caractéristiques capacitives et selfiques du support, ils sont bruités et déformés et risquent de se mélanger.
La solution réside dans la numérisation.
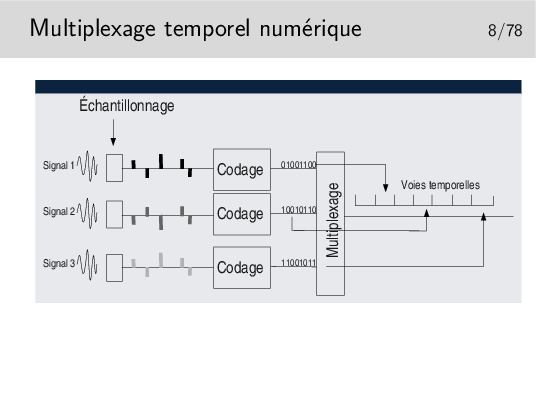
Chaque échantillon est transformé en un nombre binaire pouvant être de 12 bits par exemple, ramenés par des techniques de compression à 8 bits.
En téléphonie par il existe deux techniques principales de codage standardisées par le document ITU-T G711, toutes deux respectent la loi de Shannon édictant qu’il faut échantillonner à 8KHz, donc un échantillon toutes les 125µs. Elles divergent sur les points suivants:

Les données sont découpées en séquences de longueur variable qui sont ensuite injectées sur le même support, les unes à la suite des autres. Il n’y a pas d’ordre à priori. Si une seule source émet elle a toute la bande passante du support à sa disposition. Si n sources émettent simultanément elles disposent chacune de 1/n de la bande passante (si leurs données sont de taille égales).
Les séquences ne doivent pas être trop longues car alors le support est dédié trop longtemps à une seule source.
Les séquences doivent pouvoir être identifiées pour pouvoir les reconnaître à la réception et les remettre à leur bon destinataire. Elles sont munies d’une «étiquette» d’identification qui peut être un numéro de canal ou une adresse de réception.
Le canal est virtuel, il n’existe que si des données sont présentes.
Ce mode de multiplexage est utilisé pour le transfert de données. Il est universellement répandu: ethernet, IP (donc Internet), etc...
Les séquences de données sont appelées «paquets».
Parfois les paquets de données sont de taille constante, on les appelle alors des cellules (réseau de type ATM par exemple).







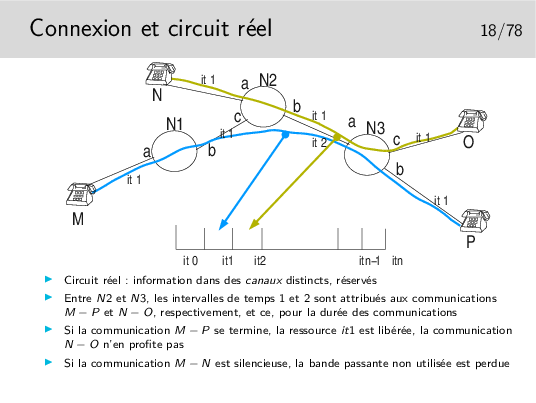
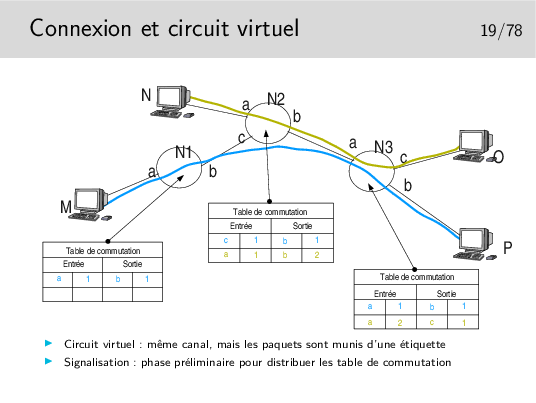
Les paquets issus de M et à destination de P sont munis d’une étiquette 1 en M. Elle reste 1 après passage dans tous les noeuds. Sans doute la communication M-P a-t’elle été établie la première.
Les paquets issus de N à destination de O sont munis d’une étiquette 1. En sortie du premier noeud traversé cette étiquette devient 2 car l’étiquette 1 est déjà attribuée à une communication.
La commutation de circuit virtuel consiste à échanger des étiquettes dans les noeuds et à orienter les unités de données (les paquets) vers les bonnes interfaces de sortie. Le chemin est un chemin d’étiquettes. Celles-ci (les étiquettes) sont réservées lors de l’établissement de la communication.


Relation célérité de la lumière dans le vide (c), fréquence (f) et longueur d’onde (λ): λ f = c
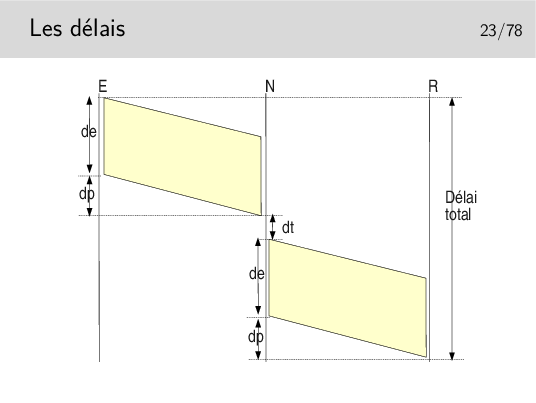
Délai total = 2 de + 2 dp + dt si un seul nœud intermédiaire et si les débits sont les mêmes sur les tous les liens.
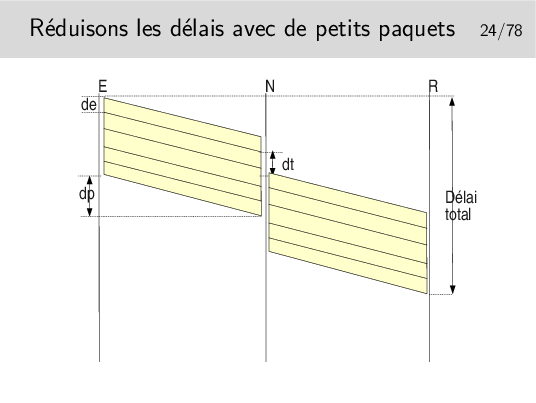
Les interfaces des nœuds fonctionnent en parallèle. Une interface peut recevoir pendant qu’une autre émet. Il reste cependant le temps de traitement, c’est à dire le temps mis par l’unité centrale du nœud pour déterminer vers quelle interface de sortie il faudra acheminer le paquet, plus le temps passé dans les mémoires files d’attente.


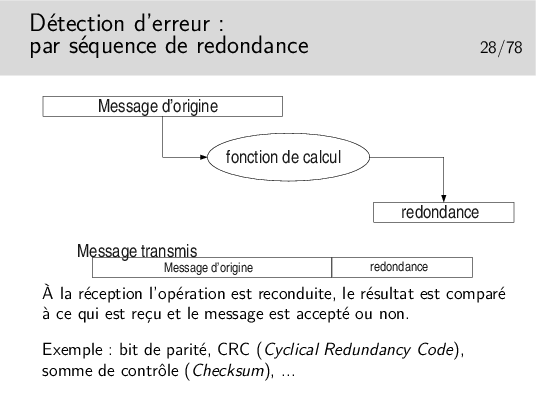
Dans les cas très répandus où les opérations de détection d’erreur sont simples et où les algorithmes ne permettent pas la correction immédiate, on ne peut pas dire si les erreurs de transmission portent sur le message lui même ou la redondance, ou les deux. On jette tout simplement le message (on l’ignore).
On ne se pose pas, à ce stade, le problème de la correction. Ce n’est pas l’affaire de l’algorithme, on s’en remet pour cela à des mécanismes situés dans des couches protocolaires supérieures (si on en a besoin).


Cette méthode est appelée CRC (Cyclical Redundancy Code)

Le reste de la division est appelé CRC du nom de la méthode.

Facile à implémenter matériellement...
Dans l’histoire des télécomunications des réseaux et de l’informatique, un certain nombre de polynôme de CRC ont été standardisés, offrant oist une bonne capacité à détecter les erreurs, soit étant faciles à implémenter (tout est affaire de compromis). Voir http://en.wikipedia.org/wiki/Cyclic_redundancy_check\#Common_polynomials.
Existe aussi en solutions logicielles, mais plus le message est long plus il
y a de temps de calcul. Voir les implémentations en C du CRC-32, par
exemple ici:
http://www.cl.cam.ac.uk/Research/SRG/bluebook/21/crc/crc.html
Des fonctions existent toutes faites, par exemple en PHP: int crc32(string str)
voir: http://fr2.php.net/crc32

Rappel (s’il en est besoin): si un mot Z vaut 1010, alors son inverse (on dit aussi son complément à 1) vaut 0101 et peut être noté Z (Z barre).


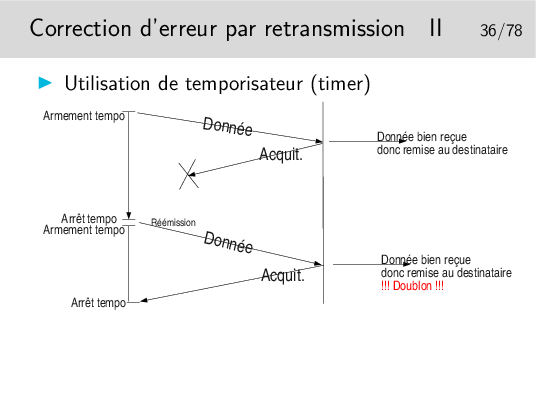
Où comment se créer d’autres problèmes en voulant en régler un... Et maintenant comment on fait pour éviter les doublons ?
C’est une règle, hélas, très générale, en Réseaux, que de se créer de nouveaux problèmes en apportant des solutions à d’autres...
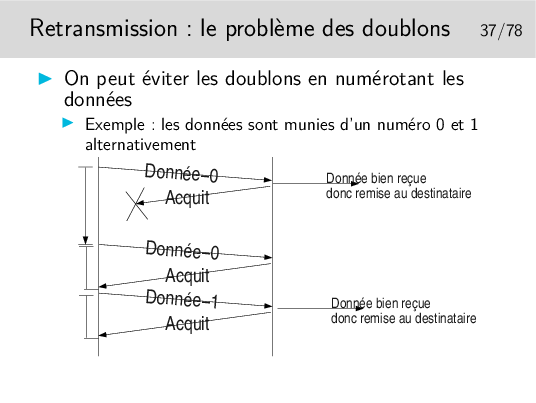
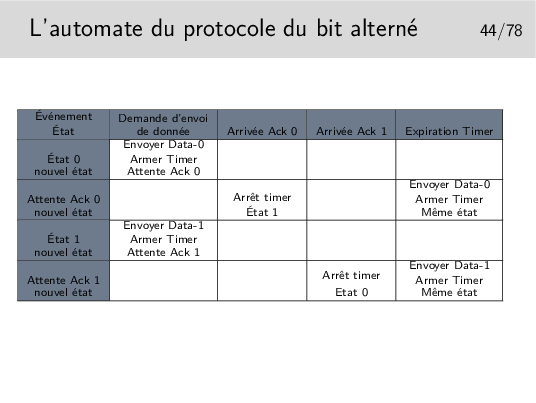
À chaque fois qu’il reçoit un acquittement il pense que celui-ci concerne les données précédemment émises, il vide les tampons mémoires qui les contenaient.
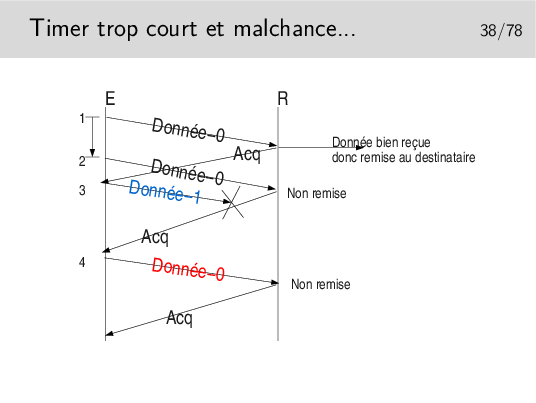
Ainsi, en 4, s’il y a une nouvelle donnée à envoyer ce sera Donnée-0 (pas le même contenu qu’au début du scénario), or le récepteur voyant arriver à nouveau un numéro 0 le rejettera. Le numéro est censé représenter les données, on ne compare pas celle qu’on reçoit avec les précédentes. D’ailleurs celles-ci ont été livrée à l’entité de destination, elles ne sont pas gardées en mémoire.
Dans ce scénario le segment Donnée-1 n’est pas reçu mais il est considéré par l’émetteur comme bien reçu. Le segment Donnée-0 suivant est bien émis et bien reçu mais il n’est pas remis à son destinataire final... Tout va mal dans ce scénario!
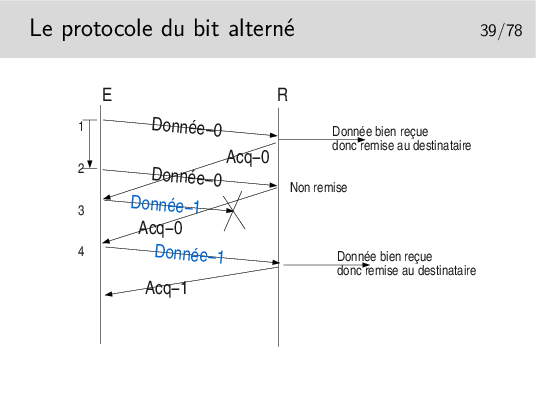
Les acquittements portent les numéro des données qu’ils acquittent. Ainsi, en 4, on reçoit à nouveau Acq-0, alors qu’on attendait Acq-1, il y a un problème, le contenu de Donnée-1 précédent est toujours en mémoire (on ne le vidra que sur réception de Acq-1), on peut donc réémettre Donnée-1 (le même message que précédemment).


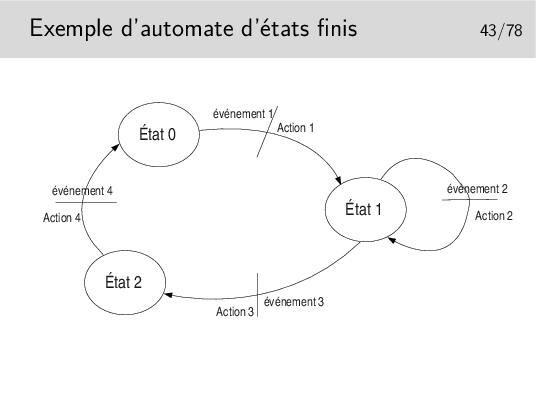
Au départ l’automate est dans un certain état, disons l’état 0 par exemple. Seul l’arrivée de l’événement 1 peut faire que l’automate passe dans l’état 2. Au passage dans ce nouvel état l’action 1 sera effectuée. Un événement ne fait pas toujours changer d’état, on l’illustre ici par l’état 1, dans lequel on reste après que soit survenu l’événement 2 et que l’action 2 ait été effectuée.
Cette représentation est proche de la formalisation mathématique des automates par les «réseaux de Petri».
La représentation schématique est intéressante car elle est souvent plus facile à comprendre (lorsqu’il n’y a pas trop d’états ni d’événements). Cependant elle ne permet pas de s’assurer que tous les cas possibles de relation événement/transition soient envisagés. Il faut alors recourir à la représentation de l’automate sous forme de tableau.

On dit que la fenêtre est «tournante» ou «glissante» selon la représentation qu’on en fait. Voir le transparent suivant.
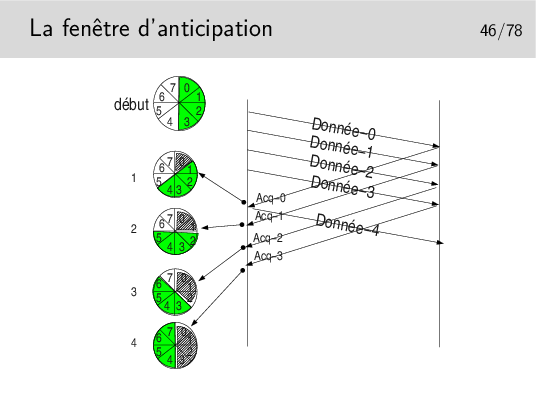
Paramètres: les segments de données sont numérotés modulo 8. La fenêtre d’anticipation est de 4.
On ne peut pas émettre plus de 4 segments à la suite si on ne reçoit pas pendant ce temps un acquittement. Lorsqu’un acquittement arrive, la fenêtre «tourne» d’un pas, le tampon mémoire contenant la donnée correspondant à l’acquittement est libéré, la donnée est considérée comme bien envoyée, on l’efface. En pratique on ne l’efface pas, on considère son emplacement mémoire comme libre. Sur le schéma ci-dessus, on indique cette «libération mémoire» par une zone grisée dans la fenêtre.
Départ: la fenêtre englobe les numéros 0 à 4. On commence l’envoi. L’acquittement pour la donnée 0 arrive en 1. La fenêtre tourne et englobe 1 à 4. Le segment 4 devient éligible à l’émission. Il est émis si une donnée est à émettre. Le tampon mémoire contenant Donnée-0 est effacé. En 2 l’acquittement pour Donnée-1 arrive, la fenêtre tourne et englobe maintenant 2 à 5. Etc.

Un émetteur et un récepteurs ne fonctionnent pas obligatoirement à la même vitesse (au même débit). Les tampons mémoire de réception se vident lorsque les applications destinatrices viennent y puiser les données reçues. Si la machine de réception est lente, si l’application réceptrice prend trop de temps à traiter les données et ne vient pas les retirer suffisamment rapidement des tampons de réception, ceux-ci se remplissent dangereusement. Lorsque les tampons sont pleins les données à recevoir seront perdues. Le contrôle de flux permet d’éviter ces pertes en évitant que les données ne soient envoyées.
Le contrôle de flux pourra être couplé à des mécanismes d’acquittement, ce sont les trames RR et RNR du protocole HDLC-LAPB que nous verrons plus loin : RR pour Receiver Ready ou encore «tout va bien, envoyez!», RNR pour Receiver Not Ready ou encore «OK, j’ai bien reçu vos données mais arrêtez vous quelque temps».



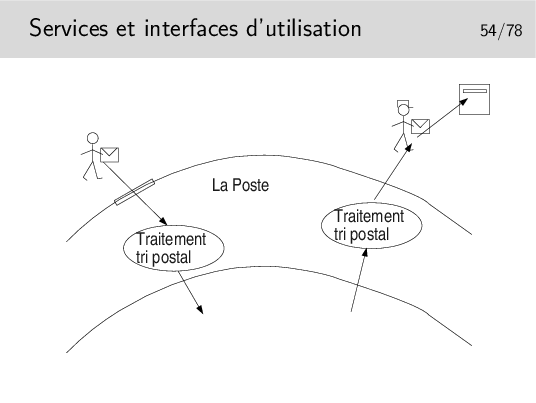
La Poste offre un SERVICE
On accède à ce service par des moyens appelés, en terme «réseaux», des PRIMITIVES DE SERVICE.
On interagit avec le service via les primitives de service dont le paramètre principal est une sorte d’adresse: l’adresse où est situé le bâtiment de La Poste pour aller «poster» sa lettre, l’adresse du destinataire de la lettre pour que le postier sache dans quelle boite aux lettres déposer celle-ci. Cette sorte d’adresse est appelée en termes réseaux le POINT D’ACCÈS AU SERVICE (le Service Access Point ou SAP).
Notion de couche, d’interface entre couches et d’indépendance entre couche.

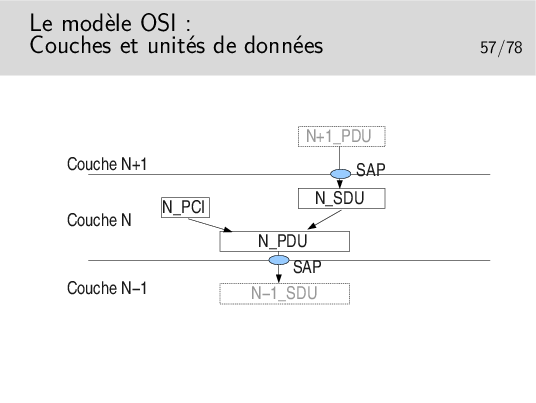
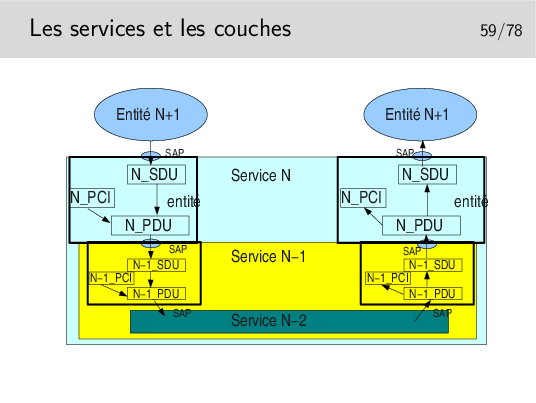
L’unité de donnée fournie par l’utilisateur est une unité de donnée à SERVIR. C’est une UNITE de DONNEE de SERVICE: une SERVICE DATA UNIT (SDU) en anglais.
La couche assurant le service utilise un certain mécanisme qui lui est propre, un protocole particulier, nécessitant un échange de données spécifiques. Ces données protocolaires n’ont rien à voir avec les données utiles, elles servent à la gestion du transfert de celles-ci.
Les données protocolaires (Protocol Control Information) sont ajoutées au segment de données utiles (les données de service, la SDU) pour former une nouvelle unité: l’unité de données de protocole ou PROTOCOL DATA UNIT (PDU).

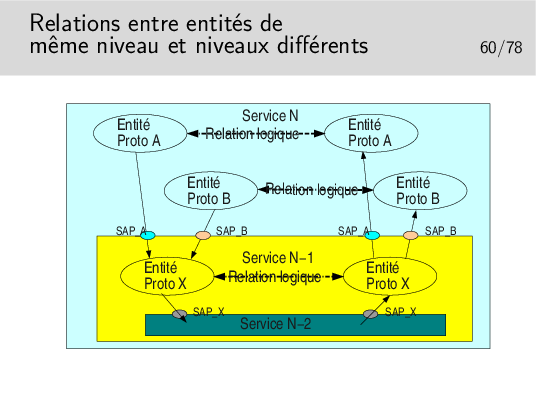
La figure ci-dessus est un exemple de ce qui est possible. Un service N met en œuvre deux types de protocoles différents pour assurer un service. Les entités protocolaires A peuvent communiquer entre elles. De même pour les entités protocolaires B. Les entités A ne peuvent communiquer avec les entités B car elles ne «parlent pas» le même langage (le même protocole).
Il est possible que les entités A et les entités B utilisent le même protocole X sous jacent (de couche N−1). Lorsque l’entité A de gauche émettra un PDU vers l’entité A de droite, il faudra que ce PDU soit muni de l’identité du SAP entre l’entité A (niveau N) et l’entité X de niveau N−1 (donc SAP A). Sinon l’entité X de droite ne saurait pas vers quelle entité réceptrice A ou B envoyer le PDU. De même pour les entités B.


Niveau physique et niveau liaison: on ne traverse pas le réseau.

Rappel de l’épisode précédent (niveau physique et niveau liaison): on ne traverse pas le réseau!
Épisode présent (niveau 3): on traverse le Réseau!

Tout ceci est très théorique. En pratique, il faut considérer ce niveau transport par type d’architecture: IP, Novell IPX, AppleTalk, IBM SNA, Decnet de Digital (racheté par Compaq, racheté par HP).


Tout ceci est à nouveau très théorique. Il faut le replacer dans le contexte de chaque architecture (IP, IPX, etc.)
La couche application, qu’on «résume», ici, d’une seule phrase est la plus complexe de toutes dans la réalité des recommandations ISO et ITU-T. Même si ses mérites sont grands, sa complexité et le peu d’outils de développements (API) ont fait qu’il n’existe pas beaucoup de réalisations pratiques (courrier électronique X400, annuaire X500 et quelques autres). Ces applications ont vu le jour vers la fin des années 80, à une époque où l’Internet se répandait déjà beaucoup dans les réseaux du monde de l’enseignement et de la recherche. Le début des années 90 a été décisif, après ne courte période d’incertitude, l’ouverture des standards autour de IP, face à au monde OSI plus fermé à fait pencher la balance en faveur de IP.
Aujourd’hui, il reste cependant le modèle, incontournable, tout au moins pour les couches bases. Il nous aide à placer les concepts et les fonctionnalités des différents réseaux qui existent.

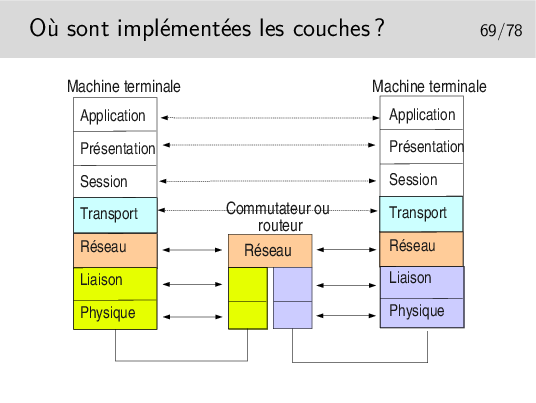
Toutes les couches sont implémentées dans les machines terminales.
Seules les couches 1 à 3 sont nécessaires dans les machines du cœur de réseau.
Il est très important de noter l’indépendance entre les couches. Voyez ici les couches physique et liaison concernant le lien coté gauche et le lien coté droit. Ces niveaux peuvent être totalement différents du point de vue physique mais aussi du point de vue couche liaison. On pourrait avoir, coté gauche un lien Ethernet sur paire torsadée et de l’autre un lien sur fibre optique.
Les débits peuvent aussi être différents. On pourrait avoir 1GB/s coté gauche et 155Mb/s coté droit.
Les couches Physique et liaison sont en général implémentées sur un même support matériel, une carte d’interface du type de celle que vous pouvez avoir sur votre ordinateur personnel
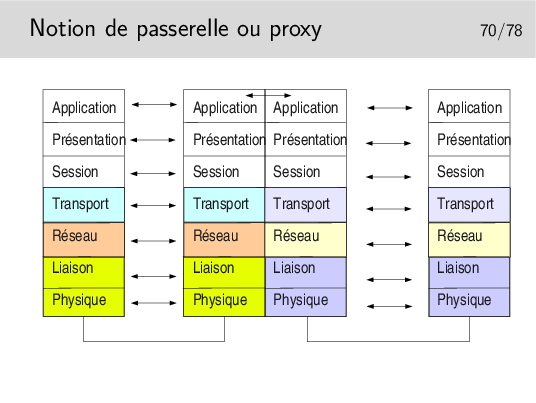
Toutes les couches sont implémentées dans la machine intermédiaires. La couche application réalise une traduction des données pour les adapter à l’application destinatrice. Les protocoles mis en oeuvre à gauche peuvent être tous différents de ceux de droite.
Dans le cas d’un proxy de type Web, les protocoles sont les mêmes à gauche et à droite, mais on oblige toutes les requêtes à passer par l’application intermédiaire (on imagine par exemple un client Web à gauche et un serveur à droite). Cela permet de réaliser des caches permettant de mémoriser les documents déjà téléchargés, afin de les renvoyer plus rapidement sans encombrer le réseau à nouveau.
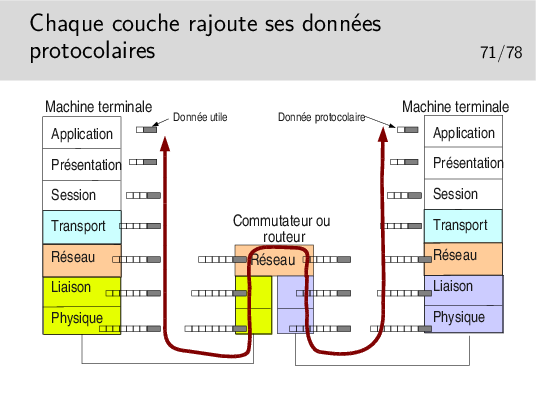
Notion de rendement: rapport entre le volume des données utiles et le volume total de données véhiculées sur un niveau.
Par exemple, pour une application cliente telnet, sur TCP IP sur Ethernet (nous verrons ces protocoles plus loin dans le cours) il est courant d’envoyer les données octet par octet dans le sens client vers serveur (au rythme où sont frappées les touches du clavier). Pour chaque octet envoyé, telnet ne rajoute rien mais TCP (niveau 4) rajoute au moins 20 octets (plus 12 avec les options des implémentations TCP d’aujourd’hui), IP (niveau 3) rajoute 20 octets. On a donc au moins 1 + 20 + 20 = 41 octets et au plus 1 + 20 + 12 + 20 = 53 octets. Dans le cas 41 octets, Ethernet rajoute 5 octets de bourrage pour arriver à la taille minimale requise, donc 46 octets. Par ailleurs Ethernet rajoute 18 octets d’informations protocolaires donc 46 + 18 = 64 octets dans un cas et 53 + 18 = 71 octets dans l’autre.
Le rendement est de 1/64 dans un cas et 1/71 dans l’autre. Ce n’est pas très efficace mais c’est ainsi!

Il existe aussi l’ICANN (The Internet Corporation for Assigned Names and Numbers) société de droit privé destinée à remplacer IANA. L’ICANN a été fondée en 1998 et on a parfois du mal à faire la distinction entre ses responsabilité et celles de IANA qui continue d’exister.
Voir un article de synthèse sur ce lien: http://www.renater.fr/Projets/ICANN/


Les RFC sont en ASCII 7bits pur... Quelques activistes à l’IETF osent militer pour y introduire un peu de HTML (au moins pour le renvoie vers les sections ou la table des matières): http://www.catb.org/~esr/rfcs-in-html/index.html
Les RFCs sont classés dans leur ordre de parution, il n’y a pas de classement thématique (hors les std).
Parmi les RFCs du premier avril citons par exemple celui spécifiant le protocole permettant d’envoyer des messages subliminaux (rfc1097), celui spécifiant comment utiliser IP sur une couche liaison de type «pigeons voyageurs» ou plus exactement des «avian carriers» (rfc1149) le MTU des messages étant proportionnel à la longueur de la patte de l’oiseau...
Mais tous les RFC «premier avril» ne sont pas des plaisanteries... Le 777 est par exemple celui qui spécifie ICMP (Internet Message Control Protocol), et ce protocole est loin d’être humoristique...

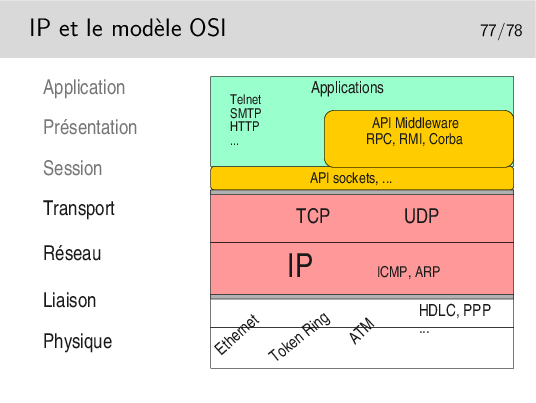
Clairement, IP est au niveau 3 et TCP/UDP au niveau 4.
Quand bien même ces protocoles ne sont pas conformes à ceux qui ont été spécifiés pour le modèle OSI, on peut leur trouver ces places dans le modèle.
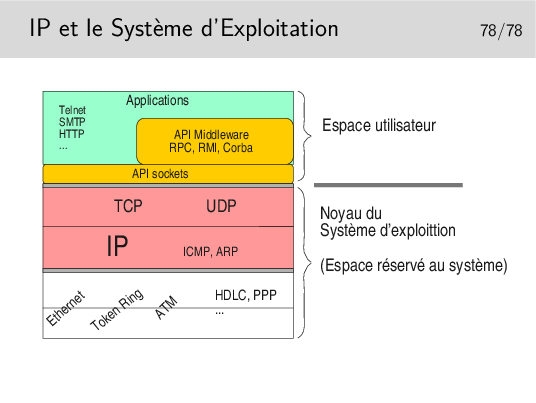
Les couches protocolaires jusqu’au niveau 4 sont inclues dans le noyau. Les applications (les programmes des utilisateurs) y accèdent via des interfaces qui les masquent.
Ces interfaces sont constituées par des bibliothèques de fonctions formant des APIs utilisables par les programmeurs d’applications. La plus répandue est la bibliothèque socket tout à fait bien adaptée aux protocoles Internet (TCP, UDP, IP). Les couches protocolaires sont vues comme des fichiers qu’on écrit ou qu’on lit. Le transfert de données est aisé puisqu’il se fait comme avec des fichiers. Le portage est aisé vers le monde Windows qui implémente aussi cette interface programmatique issue des Unix de Berkeley (les sockets BSD).
Un autre type d’API est lui aussi très répandu puisqu’il est utilisé pour NFS et NIS. Au départ spécifié par SUN dans les années 80 il est depuis universel sous Unix. Il s’agit des Remote Procedure Calls ou RPC. La couche RPC offre une abstraction du réseau et permet d’appeler des fonctions en local alors qu’elles s’exécutent à distance.
Le concept a été poussé encore plus loin et adapté aux langages orientés objet comme C++ avec CORBA (Common Object Broker Architecture) qui permet d’appeler des méthodes sur des objets situés sur des machines distantes. Cette interface n’est cependant pas standard (du point de vue API) et plusieurs implémentations existent, la plupart commerciales et d’autre libres comme ORBit qui est utilisé par GNOME sous Linux.
Ce document a été traduit de LATEX par HEVEA