TP - La QoS dans les réseaux IP
Automne 2023
Le concept de Qualité de Service ou QoS (Quality of Service) dans le domaine des réseaux recouvre «l’ensemble des mécanismes permettant de contrôler la gestion du trafic réseau afin d’assurer que le réseau satisfasse bien les besoins de service des applications».
Deux types de mécanismes peuvent être identifiés selon que l’on considère la QoS du point de vue global sur la totalité du réseau ou du point de vue particulier sur chaque équipement (routeur).

D’une manière générale, comme l’illustre la figure 1, une politique de QoS sur un équipement réseau se résume à trois grandes questions :
Chacune des quelques politiques de QoS de ce TP va répondre à sa manière à ces trois questions.
Note : Pour en savoir plus, je peux vous conseiller le wiki suivant, pas trop long, pertinent et bien rédigé : http://pteu.fr/doku.php?id=informatique:cisco:qos
Le réseau de test est architecturé comme le montre la figure 2.

Les machines terminales sont des PCs munis du système d’exploitation Linux. Le mot de passe administrateur vous sera donné en début de séance.
Configuration du réseau :
Lorsque aucune demande explicite de QoS n’est soumise à un routeur celui-ci utilise par défaut un mécanisme Fair Queueing sur ses interfaces.
Vous allez maintenant expérimenter ce mécanisme.
Faites les essais suivants en notant pour chacun le débit annoncé :
Question : Que constatez-vous ?
Vous remarquerez que nous n’avons pas encore paramétré la QoS.
Le Fair Queueing est un peu plus riche que cela. En fait, cette stratégie (historiquement ancrée dans la philosophie best effort et dans le monde IP) sait accorder plus de poids à certains flux par rapport à d’autres. On l’appelle alors Weighted Fair Queueing.
Deux concepts dans cette expression : fair queueing d’une part et weighted d’autre part, i.e. une notion de juste traitement de file d’attente et une notion de poids. Le fair queueing est un mécanisme assurant un traitement équitable à tous les flux en termes de nombres d’octets émis. Ainsi, par exemple, si dans la file 1 on a un
paquet de 100 octets et dans la file 2 deux paquets de 50 octets alors on émettra un paquet de la file 1 et deux paquets de la file 2.
Le mécanisme WFQ mis en œuvre de base par Cisco repose sur l’utilisation du champ TOS de l’entête IP des paquets qui circulent, plus exactement les bits dits de précédence qui sont les trois bits de poids fort de l’octet TOS. Notez que cette information est transportée par les paquets eux-mêmes. Ce poids peut être attribué par l’émetteur, ou modifié par n’importe quel équipement IP sur le réseau. Mais regardons ce qu’il se passe lorsque le routeur doit traiter un paquet qui comporte une indication de précédence.
Note : Dans la terminologie Cisco, ce mécanisme porte le nom de Flow-Based Weighted Fair Queueing (par opposition au Class-Based Weighted Fair Queueing que l’on abordera ensuite). Généralement les termes fair queueing, weighted fair, weighted fair queueing, flow based weighted fair queueing, sont tous synonymes et désignent le mécanisme que l’on trouve par défaut sur les équipements IP (PC, routeurs, etc.).
Avec la commande de niveau interface enlevez le mode fair-queue sur l’interface série du routeur de gauche. Vérifier le résultat avec show interface s0/0/0. Pour cela, placez-vous dans la fenêtre gtkterm de la machine 1 :
Maintenant, refaites les essais précédents, sans flux de fond pour commencer puis lancez le flux de fond et recommencez.
Note : la commande show interface s0/0/0 affiche un certain nombre de compteurs que vous pouvez remettre à zéro avec clear counter s0/0/0 (ou clear counters).
Question : Que constatez-vous ?
Comment expliquez-vous le phénomène observé lorsqu’il y a du flux de fond ?
Avant de passer à l’action prenons le temps de quelques explications spécifiques à nos équipements.
Historiquement (jusqu’à l’IOS 1 15.0), Cisco proposait principalement les stratégies de QoS suivantes :
Ces stratégies étaient assez simples à comprendre. On a une séparation claire entre la notion de priorité d’une part (certains flux passent plus tôt, avant les autres), et la notion de bande passante d’autre part (certains flux ont droit à plus de place que d’autre sans forcément passer plus tôt). Par contre ces stratégies ne sont pas forcément pratiques à utiliser
en condition réelle...
Dans le même temps (à partir d’IOS 12.0), Cisco a commencé à introduire une façon de paramétrer la QoS légèrement différente, appelée Class Based Queuing (CBQ). On retrouve un peu tous les mécanismes précédents, par contre ils sont organisés autour de la notion de classes de flux, un mécanisme un peu plus générique.
Les stratégies disponibles sont :
Low Latency Queuing (LLQ) : on retrouve le principe de flux prioritaires sur d’autres. On peut déclarer qu’une classe (ou flux) a une priorité stricte sur la class-default (i.e. tous ses paquets sortent avant). On peut également paramétrer le flux LLQ, en lui spécifiant une portion de bande passante minimale garantie pour chacun. Plus précisément, il s’agit de l’algorithme du token-bucket. Si l’on n’est pas en situation de congestion (c’est-à-dire qu’il y a de la bande passante non consommée par d’autres flux) notre flux prioritaire peut dépasser cette valeur. Par contre, en cas de congestion, le flux aura ce minimum garantit mais ne pourra pas le dépasser (des paquets sont détruits). Notons que la stratégie LLQ est ainsi nommée car elle bénéficie d’une latence faible et constante grâce au token bucket (intéressant pour de la voix sur IP par exemple).
Notez que dans la documentation Cisco on désigne parfois cette stratégie par priority policy.
Class Based Weigthed Fair Queuing (CBWFQ) : c’est un peu un mélange entre les principes du Weigthed Fair Queuing et du Custom Queueing historique décrit plus haut. Bref, les différents flux sont caractérisés non pas par le TOS, mais par une classe au sens Cisco. Et à chacune de ces classes on va allouer une portion de bande passante, selon l’algorithme du Custom-Queuing.
Notez que dans la documentation Cisco on désigne parfois cette stratégie par bandwidth policy (par opposition à priority policy).
En général, on paramètre une politique de QoS, avec une seule classe LLQ pour le flux prioritaire, et on répartit le reste de la bande passante avec plusieurs flux CBWFQ.
Vous trouvez cela compliqué ? 2 Attendez de voir quand on va le paramétrer...
La documentation Cisco (voir par exemple «Modular Quality of Service Command Line Interface» en annexe ??) résume cela en 3 étapes :
Le principe de base est de définir des classes de flux. Lorsqu’un nouveau paquet arrive, il faut que le routeur devine dans quelle classe le ranger. Historiquement, on faisait ça directement avec des Access List (ACL), en se basant sur les champs TCP-IP traditionnels (adresse IP source destination, protocole de transport, numéro de port source destination)...
Cette notion de classe apporte plus de souplesse, plus de critères de classification. On peut même encapsuler des classes dans des classes ; on parlera alors de classes hiérarchiques. (Ça fait rêver non ?)
Les critères relèvent typiquement :
En mode configuration définissez deux access-list que vous appellerez 101 et 102. La liste 101 concernera le flux de test (1 → 3), la liste 102 concernera le flux de fond (2 → 3). Repérez bien les numéros de port UDP que vous avez choisis.
La syntaxe peut être la suivante :
access-list
| num_acc_list |
| <100-199> |
| permit |
| deny |
| udp |
| tcp |
| ip |
| icmp |
| host ip_src |
| any |
| any |
| host ip_dst |
| eq |
| gt |
| lt |
| neq |
| xyz |
| port_dst |
En vous aidant de l’annexe ??, configurez les class-map suivantes :
Vérifiez votre configuration avec show class-map.
Notez qu’il y a une dernière classe à notre disposition, la class-map default, dans laquelle atterrissent les paquets qui ne rentrent pas dans les autres classes.
Voila, nos classes de flux sont prêtes, nous allons pouvoir faire de la QoS dans quelques instants...
Le mécanisme LLQ assure que le trafic «important» est transmis avant le trafic «d’importance moindre». Ce mécanisme a été pensé pour du trafic de type voix sur IP, c’est-à-dire du trafic qui requiert une faible latence, mais qui n’est pas forcément très gourmand en bande passante. Par conséquent, on s’arrange d’une part pour faire passer les paquets LLQ avant les autres, d’autre part on ne les stocke pas dans des longues files d’attente (et par conséquent on s’autorise volontiers à perdre
des paquets LLQ, notamment dans le cas où l’on veut limiter la bande passante accordée à LLQ).
Créez une policy-map (que vous pourrez appeler ma_qos ), qui travaille sur la class flux13, en déclarant cette classe strictement prioritaire (mot clef priority, sans paramètre).
Ne précisez aucune autre classe.
Affectez cette politique de QoS à l’interface de sortie (i.e. l’interface série), pour traiter les paquets sortants. (En mode configuration d’interface : service-policy output ma_qos .
Vérifiez votre configuration avec show policy-map ou show policy-map inferface s0/0/0
Ce mécanisme est aussi qualifié de politique de QoS en bandwidth, par opposition à LLQ qui est une politique avec priority.
Nous allons procéder comme précédemment.
Reprenez votre policy-map ma_qos. Incluez-la class-map flux13 mais cette fois-ci, n’employez pas le mot-clef priority. (Si elle est déjà là, faites no priority).
Par contre, vous allez lui paramétrer une bandwidth percent 60.
Retirez les autres classes s’il y en a d’autres de présentes.
Ce type de configuration est, semble-t-il, assez courant dans les situations de convergence data-voip.
Tout d’abord on a un flux prioritaire en LLQ (typiquement les paquets de type VoIP, mais on peut y ajouter des paquets de signalisation divers, ICMP, les ACK TCP, etc., bref des paquets pas forcément très gros, plutôt sporadiques, mais qui peuvent être un peu bloquant pour les couches supérieures s’ils tardent à arriver). Et dans le même temps, on va répartir la bande passante restante entre les flux applicatifs, fichier, web, data, etc.
Concrètement, le flux prioritaire est paramétré avec une règle du type priority percent x , et les autres flux sont paramétrés avec des règles du type bandwidth remaining percent y .
Pour simplifier le travail des administrateurs réseau, Cisco propose en plus un mécanisme d’AutoQoS, avec un profil VoIP pré-configuré, et un profil Entreprise qui passe d’abord par une phase d’apprentissage.
Mais je vous propose de poursuivre plus avant les manipulations avec les stratégies qui suivent...
Les différentes stratégies de QoS que nous avons vues précédemment consistaient à paramétrer les flux qui sortent du routeur. Or, dans notre banc de test, nous avons en entrée un flux qui est très agressif et qui sature rapidement les files d’attente de notre routeur (on l’a observé en section 4). (Pensez aux attaques de type déni de service.) Fondamentalement, ça ne sert pas à grand-chose qu’il rentre plus vite qu’il ne peut sortir.
Une façon de régler le problème consiste à borner le trafic en entrée du routeur. Cela s’appelle policer le trafic. (Attention, le trafic est écrêté et non pas lissé comme le fait de la QoS en bandwidth vue en 7).
Définissez une nouvelle policy-map que vous pourrez appeler mon_policer. Cette politique va travailler sur la classe flux23, que vous paramètrerez ainsi : police rate 60000 bps, puis en indiquant conform-action transmit et exceed-action drop
Ensuite, vous attacherez cette politique à l’interface par laquelle entre les paquets du PC2 (p.ex. FastEthernet 0/1, commande service-policy input .... Notez qu’il vous faudra au préalable retirer le mode fair-queue qui est par défaut sur l’interface.
Notes : Une différence notable entre le policer et le shaping est que ce dernier gère d’une file d’attente pour absorber les pics de trafic, au lieu d’écrêter. La contrepartie est que ce mécanisme ne peut pas être configuré sur les entrées, et qu’il introduit de la latence.
La documentation de Cisco 4 nous explique que ces deux services sont implémentés selon le principe du tocken bucket.
Pour se conformer à un débit nominal paramétré (appelé CIR, pour Committed Information Rate), l’équipement considère une période de temps (appelée Tc, pour Committed Time, généralement 125ms, paramétrable, mais Cisco dit qu’il calcule tout seul la valeur optimale), au cours de laquelle il va transmettre sur un temps court, mais au débit physique de l’interface une certaine quantité de données (appelée Bc, pour Committed burst). On a alors la relation simple Bc = Tc×CIR. De plus, dans le cas du shaping qui gère des pics de débit, on s’autorise à transmettre en fait Bc+Be données (Be pour excess burst).
Autrement dit, Tc est le temps pendant lequel on remplit le seau à jetons, Bc est le nombre de jetons, et Bc+Be la capacité du seau. 5
Revenons sur le mécanisme du Weighted Fair Queueing (WFQ) vu à la section 3.
La notion de poids vient peser sur des flux et les rendre moins fair que d’autre (et donc les privilégier).
Nous disions donc que le mécanisme WFQ défini par Cisco repose sur l’utilisation du champ TOS de l’entête IP, plus exactement les bits dits de précédence qui sont les trois bits de poids fort de l’octet TOS.
Le routeur affecte un poids (weight) à chaque flux par assignation des bits de précédence de l’entête IP des paquets qui les portent. Les flux sont priorisés en fonction de ce poids. Le poids est calculé selon la formule : 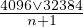 , n étant la valeur des bits de précédence (comprise entre 0 et 7). La valeur 4096 ou 32384 dépend de la version de l’IOS Cisco. Après
s’être assuré que le mécanisme de QoS de l’interface n’est pas en simple FIFO, vous pouvez consulter cette valeur avec la commande : show queue interface . Cette commande indique, par flux (ou conversation) les informations suivantes : depth/weight/discard/tail/drop/interleave . 6
, n étant la valeur des bits de précédence (comprise entre 0 et 7). La valeur 4096 ou 32384 dépend de la version de l’IOS Cisco. Après
s’être assuré que le mécanisme de QoS de l’interface n’est pas en simple FIFO, vous pouvez consulter cette valeur avec la commande : show queue interface . Cette commande indique, par flux (ou conversation) les informations suivantes : depth/weight/discard/tail/drop/interleave . 6
Avec cette méthode nous allons pouvoir affecter une partie de la bande passante aux flux que nous voulons. La méthode est la suivante : si nous affectons les précédences 1, 2, 3, 4, 5, 6, 7 respectivement à sept flux et la précédence 0 à vingt flux (arbitrairement 20 pour l’exemple) nous pourrons déterminer ce que nous pourrions appeler le total des précédences :
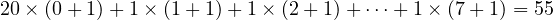
Chaque flux de précédence 1 à 7 prendra [(n + 1)∕total] parties de la bande passante, soit respectivement 2∕55, 3∕55, 4∕55, …, 8∕55 parties. Les 20 flux de précédence 0 prendront chacun 1∕55 de la bande passante.
Question : Si nous avons uniquement deux flux, dont un à la précédence 0 et un à la précédence n, quelle sera la part de bande passante pour chaque flux en fonction de n ? Faites le calcul pour chaque valeur possible de n en considérant une bande passante globale de 64 Kb/s.
Est-ce que vous retrouvez les chiffres mesurés au 3 ?
Nous reprenons nos deux flux maintenant bien connus.
Affectation de précédence au flux 1 → 3. Une manière d’effectuer cela est de créer une route-map au niveau de configuration de base. Cette route-map portera un nom, par exemple rmap1, elle aura pour numéro de séquence 0. On lui fera correspondre l’access-list caractérisant le flux 1 → 3 (match ip address num ). On affectera à cette route-map la précédence 5 (set ip precedence 5).
Notez que l’on peut également faire cela avec une policy-map (voir en annexe ??), mais on va changer un peu...
Affectation de la route-map à une interface entrante par configuration de niveau interface avec la commande ip policy route-map nom . L’interface configurée sera bien évidemment celle recevant le flux à marquer.
Bien évidemment, si vous avez choisi de procéder avec une policy-map, il faudra au contraire l’accrocher à l’interface avec service-policy input.
Les solutions modernes pour faire de la QoS offrent la possibilité de faire de la QoS hiérarchique. Il ne s’agit pas d’un nouvel algorithme, mais plutôt une façon d’utiliser les algorithmes connus, en les encapsulant les uns dans les autres.
L’idée de base est la suivante : à un niveau donné, on a une politique de QoS qui gère des paquets, et qui décide d’un faire sortir un à un instant donné. Mais ce paquet qui sort, il ne part pas sur le réseau, mais dans une autre stratégie de QoS qui englobe la première, et qui à son tour va décider du paquet qu’elle va faire sortir. Et ainsi de suite jusqu’à ce que le paquet sorte effectivement sur le réseau.
Là pour le coup on peut dire que le monde du logiciel libre ne s’est pas contenté de réimplémenter quelque chose qui existait dans le domaine commercial, mais a bien été ici un précurseur dans le domaine. Linux proposait historiquement une première implémentation de la QoS qui faisait uniquement du shaping et qui était (d’après les experts) plutôt moche. La ré-implémentation de la QoS dans Linux a le mérite d’être claire, propre, et plutôt efficace (c’est tout en logiciel, même si l’on commence à voir des choses sur carte NetFPGA). Disons-le, au jour d’aujourd’hui les équipementiers "pro" sont encore un peu à la traîne... (imho)
Les quelques stratégies de QoS vues ici sont des classiques (elles existent depuis longtemps, et sont implémentées Cisco...). De nombreuses stratégies de QoS ont été implémentées sous Linux (voir le man tc, pour traffic control). Certaines ont un intérêt surtout académique, d’autres ont un intérêt plus pratique (voir le script wondershaper).
1.Cisco IOS, abréviation de Internetwork Operating System (système d’exploitation pour la connexion des réseaux), c.à.d. le nom du logiciel des équippements Cisco ; à ne pas confondre avec des produits Apple...
2.Et encore, je ne vous ai pas parlé du Generic Traffic Shaping (GTS) permettant de fixer le débit moyen et le pic toléré... Mais Cisco non plus n’est pas très loquace sur l’algorithme derrière ce truc-là... Un double token bucket ?
3.Pour retirer une class, il suffit de la précéder du mot clef no.
4.http://www.cisco.com/en/US/tech/tk543/tk545/technologies_tech_note09186a00800a3a25.shtml
5.http://networklessons.com/quality-of-service/qos-traffic-shaping-explained/
6.Prenez la précaution de générer des flux pour que cette commande ait justement quelque chose à raconter ! Par exemple, laissez tourner le fluxUDP(emetteur/recepteur).