Programmation Système et RéseauxChristophe LohrAutomne 2018 |

GNU (jeu de mots récursif (!): Gnu is Not Unix) est une émanation de la FSF (Free Software Foundation) fondée par Richard Stallman (grand programmeur s’il en est, le père de emacs, ...) au début des années 90. Le but premier de la FSF était de créer un nouveau système d’exploitation de type Unix, totalement libre, ainsi que des outils. Le noyau de ce nouveau système existe, il s’appelle Hurd.
Indépendamment de ces travaux et en parallèle, Linux Thorvald développait Linux et toute une communauté de développeur adhérait à ce nouveau système et développait des outils, dont une bibliothèque C de base: la fameuse libc.
Dans le monde du logiciel libre le développement logiciel est de type «bazar» plutôt que de type «cathédrale» (E. S. Raymond, La cathédrale et le bazar, 1998) c’est à dire que le développement logiciel est sans direction et, de ce qui peut sembler un chaos, il en sort le meilleur mais possiblement en plusieurs solutions. Parfois les diverses solutions logicielles coexistent, parfois une est encore meilleure et prend le dessus sur l’autre. Dans le cas de la libc sous Linux il semble que la solution GNU soit la meilleure.
L’effigie de GNU et de la FSF est une tête souriante (mais non moqueuse) de gnou.
Voir le lien www.fsf.org

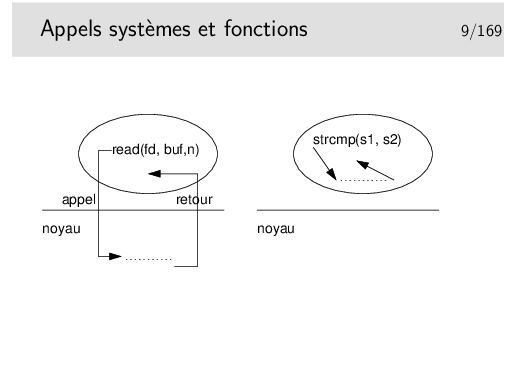
Un appel système est une fonction du plus bas niveau permettant une interaction avec le noyau du système d’exploitation. Certains auteurs appellent ce genre de fonctions des primitives.
Un appel système est une fonction dont la partie principale du corps (le code exécutable) est située dans le noyau. L’implémentation utilisable (en libc) est réduite à une préparation de contexte (le numéro de l’appel système et ses arguments sont placées dans des registres du processeur) et à un appel de l’interruption 0x80 (sur architecture x86).
Voir par exemple:
http://world.std.com/~slanning/asm/daytime_cli.txt
http://www.ruxcon.org/files/asm.pdf
Lors d’un appel système, le processeur exécute le code du noyau dans un contexte de processus, le noyau sait de quel processus il s’agit.
Et pour plus d’information: man libc, ainsi que man syscalls.

Le résultat d’un appel système peut être l’entier retourné directement. C’est le cas pour open() ou socket() par exemple, qui renvoient un entier appelé «descripteur de fichier. Ce n’est pas le cas pour stat() qui doit renvoyer toutes les informations possibles sur un fichier dont le nom est passé en argument. Dans ce cas, le résultat est complexe, il se présente sous la forme d’une structure qui doit être allouée dans l’espace mémoire du processus (par malloc(), ou par déclaration en pile). Il faut alors passer l’adresse de la structure à l’appel système afin que celui-ci puisse renvoyer un résultat correct.

Les fonctions qui rendent leur résultat via un pointeur peuvent poser des problèmes de ré-entrance dans le cas d’utilisation de threads. En effet, le pointeur indique une zone allouée par la fonction, repérée en interne par une variable de type statique (si elle est nulle on alloue, sinon on réutilise). Dans le cas d’un processus qui utilise le pointeur rendu plusieurs fois de suite il n’y a pas de problème. Dans le cas de plusiseurs threads du même processus, il n’en va pas de même, chaque thread s’attendant à trouver une donnée privée. Le problème est généralement indiqué dans le manuel de référence et les fonctions en cause sont doublées par des fonctions presqu’identiques mais «thread safe».
L’exécution d’un appel système se réalise dans le noyau. Si ce dernier ne peut pas effectuer le travail demandé, l’appel système bloque (par défaut) et le processus se trouve ainsi arrêté. Par exemple lorsqu’un processus tente de lire une socket en réseau et qu’il n’y a rien à lire, le processus se trouve bloqué. Il est généralement possible de paramétrer les «objets» bloquants (les descripteurs de fichier comme les sockets) pour que les appels systèmes soient non bloquants. Dans ce dernier cas, les appels rendent -1 et la variable ERRNO est placée à la valeur EAGAIN (EWOULDBLOCK sur BSD).
Le traitement d’une fonction normale se fait dans l’espace mémoire du processus. Il peut y avoir des appels systèmes sous-jacents, par exemples avec fopen() (appel système open()), fread() (appel système read()), fwrite() (appel système write()), etc.

Notation stat(2), gethostbyname(3): le chiffre entre parenthèses indique la section du manuel de référence où est définie la fonction: 2 pour les appels systèmes, 3 pour les fonctions normales.
Extrait du manuel de référence:
int stat(const char *file_name, struct stat *buf);
struct hostent *gethostbyname(const char *name);



Dans l’exemple ci-dessus le mot EEXIST correspond à la valeur affectée à la variable errno lorsque l’appel système open échoue lorsque les conditions indiquées sont remplies (le fichier existe mais les drapeaux O_CREAT et 0_EXCL étaient utilisés dans le open. Faire man open pour une description plus exhaustive).
Ayez le réflexe «RTFM»: Read That Fine (ou F...) Manual!
Exercice:
Les applications sont chargées en mémoire pour être exécutées.
Elles s’exécutent dans des entités appelées «processus», dans une partie de la mémoire non occupée par la noyau.
Les applications (processus) communiquent avec le noyau via des fonctions particulières appelées «appels systèmes» et parfois «primitives»



Le nom des variables d’environnement n’est pas obligatoirement en majuscules, il s’agit simplement d’une coutume qu’il en soit ainsi.
Attention, il n’y a pas d’espace de part et d’autre du signe égal (voir la syntaxe de votre shell).
Les variables d’environnement sont en général positionnées dans le Shell de l’utilisateur, via des fichiers de paramétrage tels que .bashrc.



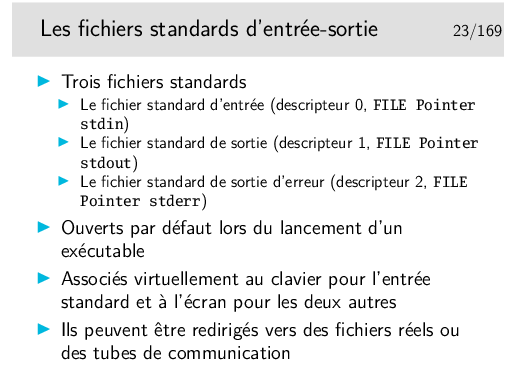
Voir plus loin les notions de descripteur de fichier et de FILE Pointer.
stdin, stdout et stderr sont définis dans /usr/include/stdio.h.
Le concept de fichier standard est surtout utile pour les redirections. Voir le mécanisme plus loin.



La communication entre processus père et fils peut se faire grâce à des tubes de communication (pipe), des sockets, de la mémoire partagée (Voir IPC SysV).
La communication entre deux processus de la même machine est aussi complexe à mettre en œuvre pour des processus locaux à la même machine que pour des processus sur des machines distantes.

La section de code entre le case 0 et le break qui suit ne sera exécutée que dans le processus fils puisque ce n’est que dans lui que pid vaut 0. Dans le père la variable pid est égale au numéro du processus fils (0 < pid < 30000).
Le même programme peut donc contenir du code qui ne sera exécuté que par l’un des deux processus. Pour le développeur, toute la difficulté sera maintenant de construire son programme en envisageant le parallélisme introduit.
Pour des raisons de clarté, il est préférable de développer le code du fils dans une fonction spécifique et d’appeler celle-ci dans le "case 0".

Le tout premier processus est le noyau lui même, de numéro 0. Sous Linux, il n’apparaît pas directement avec la commande ps, il faut demander à voir les processus parents pour le voir (on voit ainsi que init à pour père 0).
Init est le processus qui administre la machine, il lance les services, en particulier les services de connexion d’utilisateurs, les services réseaux, etc.
Sous Linux, cette valeur limite de 32768 processus est paramétrable via le fichier spécial /proc/sys/kernel/pid_max (voir le man proc).


Imaginons un fichier exécutable appartenant à root, ayant le bit set_user_ID positionné dans ses droits, exécuté par l’utilisateur dupont (uid 501 par exemple) et appelant setuid() de la manière qui suit, les droits changerons comme indiqué:
| /* début du programme */ | ruid=501 (dupont), euid = 0 (root) : droits de root |
| ... | |
| ... | |
| euid = geteuid(); | pour mémoriser euid |
| setuid(getuid()); | euid = ruid = 501 (dupont) : droits de dupon |
| ... | (saved_user_ID = 0) |
| ... | |
| setuid(euid); | ruid=501 (dupont), euid = 0 (root) : droits de root |
Certains programmes tels que les shells (/bin/sh) repassent immédiatement sous l’identité de l’utilisateur réel, pour éviter les bêtises au cas ou le programme ou le script aurait été installé avec le bit SUID...

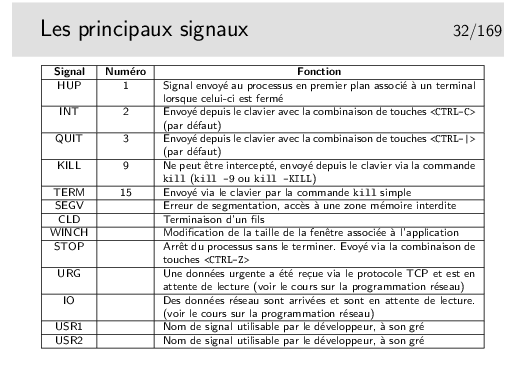
Certains signaux destructeurs font qu’un fichier de nom core soit produit dans le répertoire courant. Ce sont essentiellement les signaux SIGQUIT, SIGSEGV et SIGBUS.
Ce fichier core est une copie de l’image mémoire du processus au moment où l’erreur s’est produite, elle permet donc un débogage ultérieur avec un outil adapté (gdb par exemple). Ce fichier n’est utile que si l’on possède les sources de l’exécutable qui a «fauté», dans le cas contraire il ne sert à rien et on peut l’effacer. Il faut aussi que le source ait été compilé avec l’option -g pour que le débogage soit possible.
Le fichier core ne sert donc pas très souvent et il est fréquent que le paramétrage de l’environnement de l’utilisateur interdise sa production. Pour cela il suffit que la fonction interne du bash ulimit ait été invoquée de la manière suivante: ulimit -c 0.
Pour ré-autoriser la production de fichier core sur erreur on peut faire:
ulimit -c unlimited (voir le manuel de bash).


Lignes 1 à 3: corps d’une fonction de gestion de signal.
Lignes 5 à 9: programme principal, les pointillés symbolisent des instructions diverses propres au programme.
Ligne 9: appel à signal(). Le premier argument indique le signal SIGINT (envoyé au clavier par <Control-C>. Le second argument est l’adresse de la fonction de gestion. La fonction signal() mémorise, pour le processus, que celui-ci, s’il reçoit le signal SIGINT, devra se dérouter sur la fonction indiquée.
Remarques:

Le type rendu par signal() n’est pas toujours défini comme ci-dessus (sighandler_t). Il peut varier selon les types de libc (SignalHandler, sig_t). C’est un inconvénient mineur pour la portabilité des sources, en aucun cas pour le fonctionnement, l’essentiel étant que signal() rende un pointeur sur la fonction de gestion précédemment associée au signal.
Autre problème, de comportement cette fois: lorsque la fonction est appelée quand le signal survient, le comportement associé au signal peut être réinitialisé à son défaut juste avant d’appeler la fonction. La fonction est quand même appelée mais elle ne le sera plus. C’est le comportement traditionnel UNIX système V. En Unix BSD par contre c’est l’inverse, le déroutement vers la fonction reste associé au signal même après la première fois. Une solution pour ne pas se poser de question est de rappeler signal() dans la fonction (ainsi on «réarrme» à chaque fois).
Autre solution, recommandée, est d’utiliser sigaction(), plus complexe, plus riche, mais plus contrôlable.

Notes sur la structure sigaction:
La fonction de traitement associée au signal est indiquée dans le champ sa_handler ou dans le champ sa_sigaction (si SA_SIGINFO est indiqué dans sa_flags). Sur certaines architectures on emploie une union, il ne faut donc pas utiliser ou remplir simultanément sa_handler et sa_sigaction.

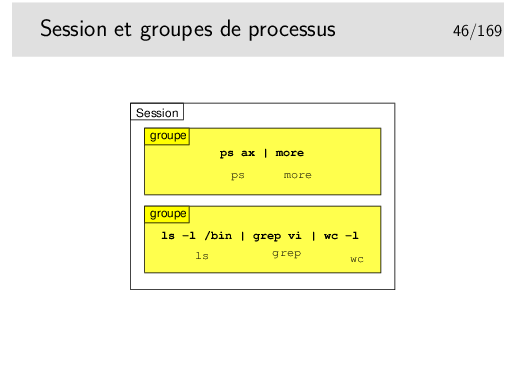
La notion de «groupe de processus» est vue plus loin.
Pour s’envoyer un signal à soi même, on peut utiliser l’appel système raise(int sig), équivalent à kill(getpid(), sig).



Les shells stockent le paramètre du exit dans une variable interne pouvant être testée. Sous bash elle s’appelle «?».
Essayez les commandes suivantes:
bash$ grep root /etc/passwd ... bash$ echo $? ... bash$ grep toto /etc/passwd bash$ echo $? ... bash$ grep toto /etc/pwd ... bash$ echo $? ... bash$ true bash$ echo $? ... bash$ false bash$ echo $?
Comment expliquez vous les réponses à la commande echo $?
Sous C-Shell la variable est status.
Le C standard recommande d’utiliser les mots clé EXIT_SUCCESS et EXIT_FAILURE pour des raisons de portabilité entre systèmes non Unix. Mais dans ce cas nous avons seulement une valeur pour indiquer un code d’erreur alors qu’avec les valeurs numériques nous en avons 255.

wait() renvoie le numéro du processus fils terminé.
Si son argument (*status) n’est pas nul, on retrouvera l’information sur la terminaison du fils à l’adresse pointée par status. Cette information nous donnera la valeur du paramètre du exit du fils s’il s’est terminé par exit(). S’il s’est terminé sur un signal nous pourrons avoir le numéro de ce signal. Voir transparent suivant.
L’appel système waitpid() permet d’attendre la terminaison d’un processus fils particulier indiqué par son numéro de processus.
Ces appels systèmes sont bloquants. Si on ne désire pas que le processus qui les appelle bloque, il faut alors les placer dans une fonction de gestion du signal SIGCLD.
Autres fonctions issues de BSD: wait3() et wait4(). Voir le manuel de référence.

On n’utilise WEXITSTATUS que si WIFEXITED rend VRAI (différent de 0).
On n’utilise WTERMSIG que si WIFSIGNALED rend VRAI.
On n’utilise WSTOPSIG que si WIFSTOPPED rend VRAI.
Certains signaux font que le processus qui les reçoit se termine en produisant un fichier image de lui-même appelé core. Cette image peut ensuite être utilisée pour déboguer le programme (signaux tels que SIGSEGV et SIGBUS).


Syntaxe de setpgid():
int setpgid(pid_t pid, pid_t pgid);
Si pid et pgid sont égaux à 0, alors le processus devient Process Group Leader
Un processus peut changer de groupe pour lui même ou pour l’un de ses fils.
Un processus Session Leader ne peut pas changer de groupe (voir ci-après).

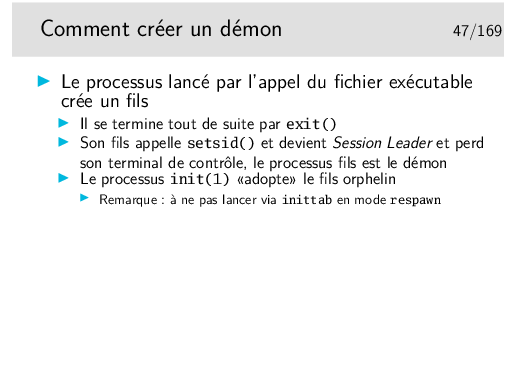
Note: voir également daemon(3) qui fait tout ça tout seul.

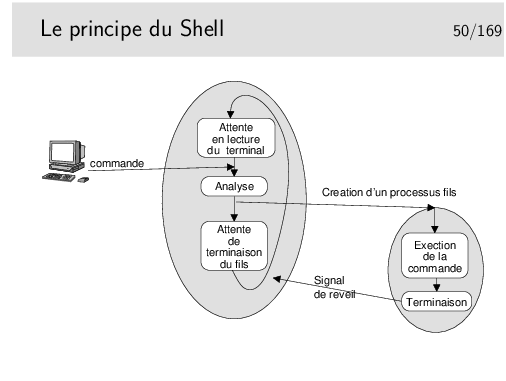
La phase «analyse» consiste pour le Shell à remplacer les métacaractères (*, ?, \, accents, etc.) pouvant être présent dans la ligne de commande. Il vérifie ensuite si la commande correspond à un alias, une fonction interne (une fonction définie par l’utilisateur dans le Shell lui même), ou une commande interne (c’est différent d’une fonction).
Dans le cas de la fonction ou de la commande interne, le Shell exécute directement ce qu’on lui demande sans créer de processus fils.
Sinon (la commande correspond à un fichier exécutable), un processus fils est créé pour exécuter la commande.
Le Shell reçoit le signal SIGCLD à la terminaison du processus fils.
Il ne reste pas an attente (wait()) si la ligne de commande est terminée par «&» (commande en background).

Il faut faire le choix de travailler avec les descripteurs ou avec les FILE pointer. Il n’y a pas de recommandation particulière, parfois il est plus aisé de travailler avec les descripteurs, parfois non.
Le type FILE, défini dans <stdio.h> s’utilise facilement, il cache une structure dont il est parfaitement inutile de connaître le contenu.
Les tubes de communication servent à la communication entre processus sur une même machine. Il en existe deux types: les tubes simples qui permettent la communication entre processus filliés (père-fils, fils-fils, ...) et les tubes nommés, plus généraux.
Les sockets cachent des mécanismes de communication en réseau mais permettent aussi la communication locale.
Pour ce qui concerne uniquement la communication entre processus sur la même machine, il existe une autre famille d’appels systèmes que l’on nomme les IPC Système V, IPC pour Inter Process Communication et Système V car ils sont issus de la version V du système Unix. Voir plus loin.

Le fait d’obtenir le descripteur le plus petit disponible est fondamental. C’est sur lui que repose le mécanisme des redirections des fichiers standard d’entrée-sorties.
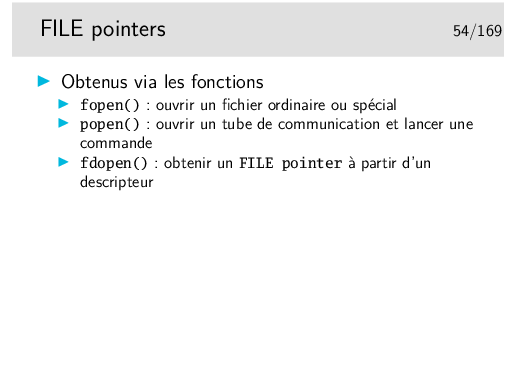
Le «FILE pointer» est en fait une structure définie dans <stdio.h>. Un typedef en fait le type FILE.
Le type FILE est un type opaque, on sait qu’il existe, on manipule des pointeurs de ce type mais on n’a pas du tout besoin d’en examiner le contenu.
Lisez le man de stdio et de stdout.


Notons également la fonction getline(), spécifique aux libc GNU, mais très souple d’utilisation pour lire du texte de taille non déterminée sur un FILE pointer.
Il y a aussi le cas de l’appel système mmap(), très prisée des développeurs soucieux d’optimiser leur code: cet appel système réalise une projection en mémoire du contenu d’un fichier. La zone de mémoire en question étant gérée par le noyau (et oui: c’est un des rares cas où du code utilisateur va accéder à une zone de mémoire noyau), on évite parfois de recopier les données entre l’espace noyau et l’espace utilisateur (cas typique du read().


Remarquer la spécification de la variable fp: c’est un pointeur sur un objet de type FILE.
On l’utilise avec les fonctions qui rendent des pointeurs de ce type, exemple ici fopen().
Vérifiez en consultant le manuel de référence pour fopen().

Un descripteur ne désigne pas systématiquement un fichier réel, il peut désigner un tube de communication ou une socket. Un fichier ouvert par fopen() est identifié par un FILE pointer qui cache en réalité un descripteur.
Notez également que getrlimit()/setrlimit() permettent de manipuler la limitation d’utilisation de différents types de ressources (mémoire, cpu, nombre de processus fils, etc.). Consultez le man.


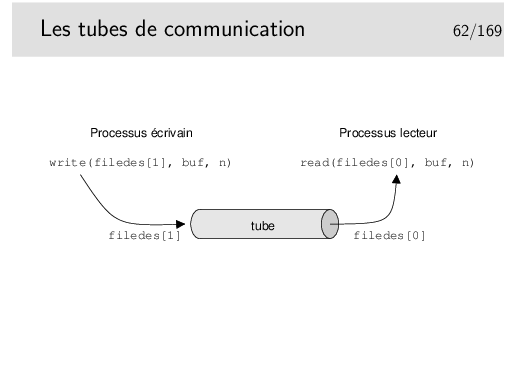
Une fonction intéressante: popen()
La fonction popen() permet de créer un tube de communication puis un processus fils dans lequel on exécute une commande Unix passée en premier paramètre. Le second paramètre de popen() permet d’indiquer si on veut lire ou écrire le tube.
popen() rend un pointeur de type FILE.
La fonction pclose() permet de fermer le tube obtenu via popen().
Notez que l’on peut aussi faire des communications entre deux processus qui n’ont rien à voir entre eux (pas relations de filiation ou autre), grâce à des pipes nommés (ou FIFO, voir man 7 pipe et man 7 fifo). Pour cela, il faut créer un fichier spécial de type pipe (voir la commande ou l’appel système mkfifo, qui est en fait une spécialisation de mknod). Ensuite, deux processus (seulement) doivent ouvrir ce fichier, l’un en écriture, l’autre en lecture, et communiquent comme via un pipe ordinaire.

Note: fcntl() permet également de poser des verrous sur des fichiers... Mais le sujet des verrous de fichiers sous Unix est éminemment complexe.

Note: voir également la fonction remove(3), qui fait soit un unlink(2) si c’est un fichier, soit un rmdir(2) si c’est un répertoire.


Rappelez-vous qu’un répertoire, même vide, contient toujours au moins deux entrées (les deux premières) qui sont «.» et «..».

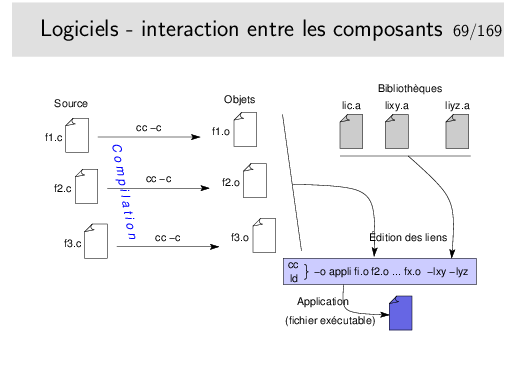

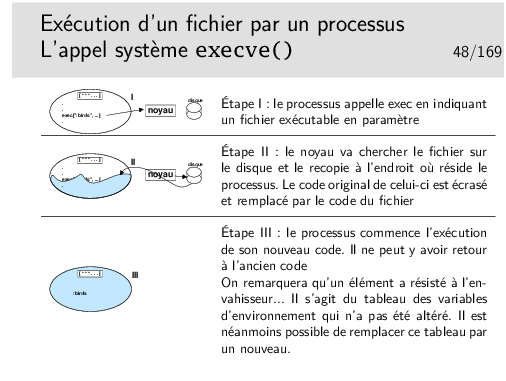
Cet exemple montre le résultat de la compilation proprement dite. Résultat intermédiaire car stoppé avant la production du binaire. On voit comment le code C standard est traduit, on voit surtout comment un appel à une fonction est traduit: un simple call fonction (avec, toutefois, auparavant la préparation du changement de contexte et ensuite la récupération du résultat, ce n’est pas si simple...).
La compilation de ce code assembleur produira un fichier objet suffixé par .o contenant la traduction binaire des instructions ci-dessus au format du micro-processeur.
Ce fichier objet ne sera pas exécutable bien que le code contenu sera formé d’instructions machine valides. Il faudra terminer le travail en reliant ce code avec celui des fonctions appelées: ce sera l’opération d’édition de liens.

La première tentative de compilation provoque une erreur sur la référence manquante à la fonction log() appelée dans notre programme. Mais soyons plus précis, il ne s’agit plus ici de compilation mais d’édition de liens. La phase compilation est en effet terminée, un fichier objet a été produit. On recherche maintenant à résoudre les références trouvées dans ce fichier objet en recherchant, entre autre, les fonctions dans des bibliothèques.
On remarque que la fonction printf() ne pose pas de problème. Sa référence est donc résolue. Mais pourquoi ?
L’édition de lien par défaut prend toujours en compte la bibliothèque standard C, la libc, dans laquelle on trouve le code compilé des fonctions standard du langage C. Par contre il n’en va pas de même pour la bibliothèque mathématique par exemple. Il faut préciser qu’elle est nécessaire dans la ligne de compilation.


Partageable: le code de la bilibiothèque n’est présent qu’une seulle fois en mémoire, mais plusieurs applications peuvent l’utiliser. À l’opposé, dans le cas de bilibiothèques statiques, le code est recopié dans chaque application qui l’utilise.










Notons que les outils strace et gdb sont implémentés en utilisant l’appel système ptrace(2) qui permet à un processus d’accéder à l’espace mémoire d’un autre (et accessoirement de faire de l’injection de code). À l’opposé, gprof s’attend à ce que le processus racompte lui-même ce qu’il fait (compilé avec -pg).
Note: l’injection de code avec ptrace permet des trucs rigolo (e.g. retty ou reptyr), mais introduit des problèmes de sécurité (e.g. le recours à prctl(PR_SET_DUMPABLE,0) dans ssh-agent...).

Pour aller plus loin, on peut utiliser des frameworks comme Valgind (http://valgrind.org/) ou cmoka (https://cmocka.org/).



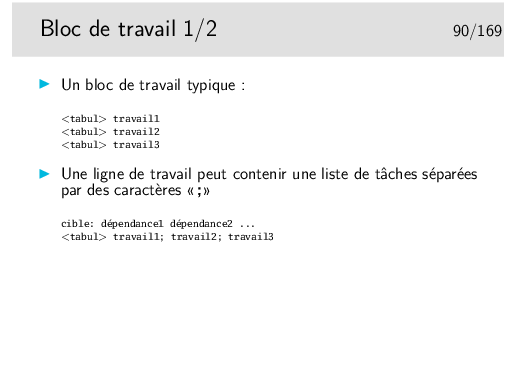


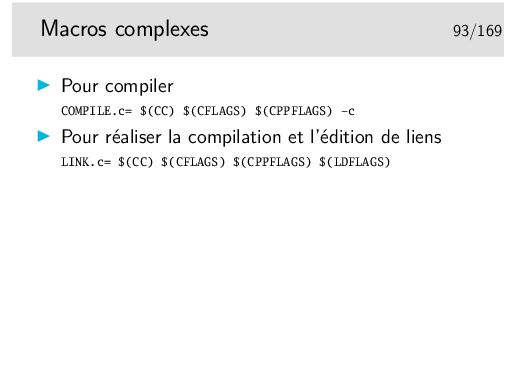

Attention à ne pas oublier un retour à la ligne en fin de fichier.
Les tabulations <tabul> sont extrèmement importantes et ne doivent pas être remplacées par des espaces, sans quoi l’outil make n’arriver pas à interpréter votre fichier Makefile.


Réponse:


Lisez lentement...:-)




Note: la clause include est une spécificité du make de GNU (qui est tout de même largement répandu). S’il existe une règle pour fabriquer le(s) fichier(s) indiqué par ce include, make l’applique (après avoir comparé les dates suivant la mécanique habituelle).
L’exemple donné ici convient bien pour les projets de petite ou moyenne taille: on recalcule les dépendances pour toutes les $(SOURCES) à la fois. Si le projet et gros, on peut vouloir recalculer les dépendances pour chacun des fichiers .c indépendément des autres. Voir l’option gcc -MMD pour cela: le compilateur compile tout (il ne s’arrête pas au pré-processeur comme gcc -MM), et en même temps fabrique un fichier de dépendance fichier.d pour chaque fichier.c, qui pourra être utilisé pour le coup d’après à l’aide de clauses include. Par contre on n’ajoute pas de règle spécifique pour les générer dans le Makefile. Cela implique donc que les fichiers .h ne doivent pas trop changer d’une fois sur l’autre, puisque les dépendances ne seront considérées que lors d’un make ultérieur...
Historiquement on utilisait la commande makedepend qui recherche également les dépendances des fichier .h, et place le résultat à la fin du fichier Makefile lui-même (pratique si make ne comprend pas les include). On avait alors l’habitude d’ajouter une cible spéciale make depend pour l’appeler. (Donc un appelait deux fois make: make depend; make all.) Cette facon de faire n’est plus trop utilisée.







Exemples :
[linux]# rpm -qf /bin/ls
fileutils-4.0-1
[linux]# rpm -q nfsEn fait, le paquetage NFS porte un nom plus complexe et est peut être installé malgré tout. Essayons avec l’option -a qui permet, en mode query (option -q) de lister tous les paquetages installés.
package nfs is not installed
[linux] rpm -qa | grep nfs
nfs-utils-clients-0.2.1-2mdk
nfs-utils-0.2.1-2mdk
[linux]# rpm -ql nfs-utils-clients-0.2.1-2mdk
/etc/rc.d/init.d/nfslock
/usr/sbin/rpc.lockd
...
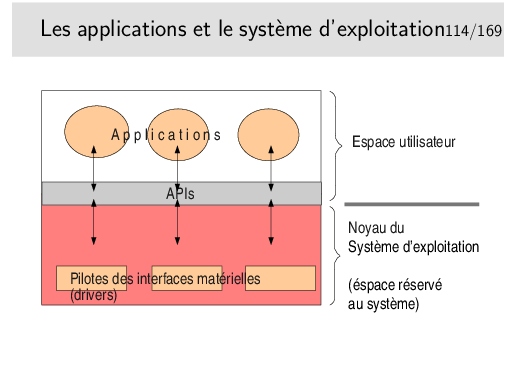
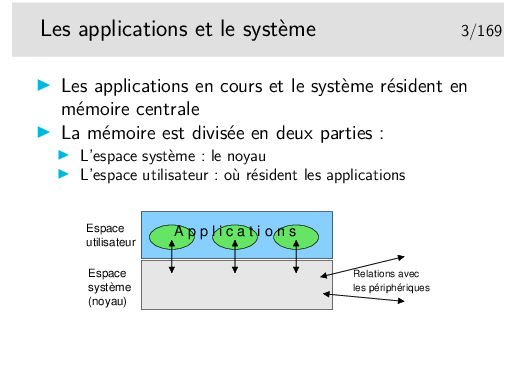
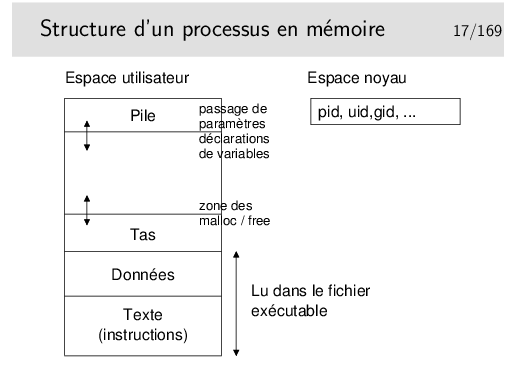
Une application informatique s’exécute dans la mémoire centrale de l’ordinateur (la RAM), sous contrôle du système d’exploitation, lui aussi chargé dans la mémoire centrale. Laissons nous imaginer que l’ordinateur ne soit représenté que par sa mémoire centrale. C’est ce veut représenter la figure ci-dessus: imaginez que le rectangle extérieur englobant est cette mémoire RAM.
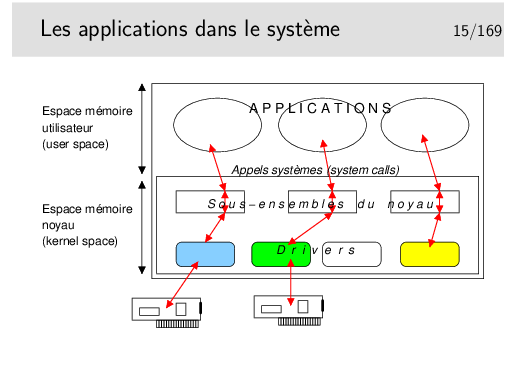
L’espace mémoire RAM disponible est divisé en deux parties: d’une part la partie occupée par le système d’exploitation lui même, l’espace «noyau» (qu’on appellera pour faire simple le «noyau»), d’autre part la partie où peuvent s’exécuter les applications qu’on appellera l’espace utilisateur.
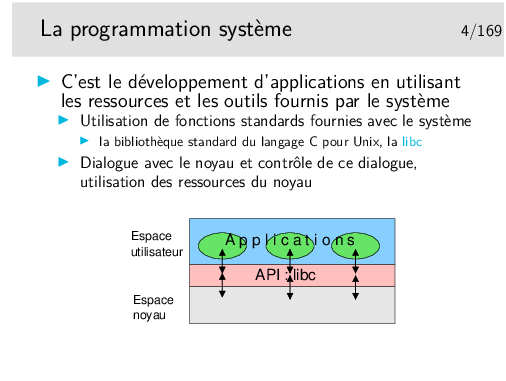
Pour accéder aux services des divers matériels périphériques (disques, clavier, souris, écran, et pour notre propos, réseau) le noyau possède des modules logiciels spécifiques de ces périphériques, des modules pouvant dialoguer directement avec eux qu’on appelle des pilotes de périphériques, en anglais des «drivers».
Les applications ne communiquent pas directement avec les pilotes de périphériques, elles communiquent avec le noyau, à l’aide de fonctions spécifiques (qu’on nomme des «appels système» ou parfois des primitives). Ces fonctions sont regroupées dans des bibliothèques de fonctions qu’on nomme des «APIs» (Application Programmer’s Interface).
Ces fonctions sont «génériques» dans le sens où elles masquent la réalité matérielle. La matériel devient une abstraction. L’API est une couche d’abstraction. Pour ce qui nous concerne en réseau et pour faire simple, l’API Réseau que nous utiliserons nous présentera le réseau comme un fichier et nous enverrons des données vers un destinataire comme nous écrivons dans un fichier (le réseau est devenu un concept abstrait).
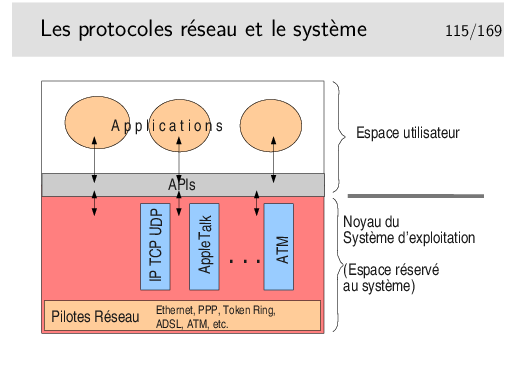
Pour ce qui nous concerne, en réseau, il est fort heureux que les protocoles majeurs soient directement implémentés au cœur des noyaux des systèmes d’exploitation. Les APIs sont là pour nous offrir une couche d’abstraction de ces protocoles. Rassurez vous, pour communiquer avec des protocoles standards tels que TCP-IP vous n’aurez pas à créer de toute pièce les datagrammes IP ni les segments TCP, ni à contrôler le fonctionnement de ces protocoles (pensez à la machine d’états finis TCP, en fait, non, n’y pensez plus). Il vous suffira d’utiliser une fonction de l’API pour ouvrir un point d’accès, de le paramétrer correctement (là il vous faudra connaître l’existence de quelques aspects du protocole utilisé mais pas beaucoup), ensuite ce point d’accès sera banalisé et vous le traiterez comme un fichier...
Magique... Presque...
Il vous faudra quand même connaître les arcanes de la programmation système en langage C ou C++ sous Unix/Linux ou Windows ou MacOS. Vous pourrez négliger ces derniers aspects si vous programmez en Java, mais alors il vous faudra maîtriser Java. Si Java ne vous plaît pas il vous reste Perl, Python, et bien d’autres langages de haut niveau comprenant de manière intrinsèques des fonctionnalités Réseau.
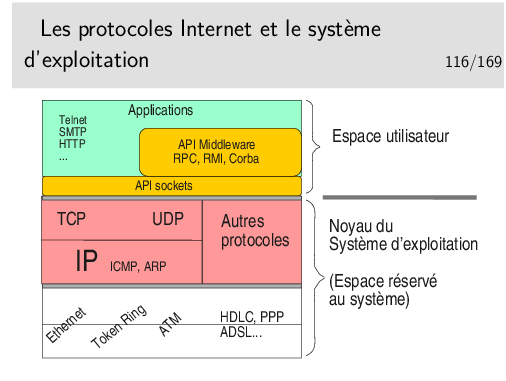
Pour ce qui est des protocoles Internet en particulier ce qui a été dit précédemment s’applique tout à fait aux protocoles des niveaux 3 et 4 OSI, donc à IP et TCP et UDP.
Ces derniers sont inclus dans le système d’exploitation et sont accessibles via des fonctions de la bibliothèque socket (inclue dans la bibliothèque standard du langage C sous Linux et bibliothèque standard WinSock (ws32) sous Windows). Les «sockets» vont nous donner une abstraction du réseau en nous le présentant comme un fichier (il est facile d’écrire ou de lire un fichier, il sera facile d’écrire ou de lire le réseau, c’est à dire, en pratique, d’envoyer ou de recevoir des octets via le réseau).
Les sockets restent cependant des outils de bas niveau, adaptées au langage C ou C++ de base et il faut construire «à la main» les protocoles applicatifs que l’on veut mettre en œuvre (les protocoles des applications, pensez au mail (smtp), au web (http), etc.). Ces protocoles s’appuient sur TCP-IP pour véhicule leurs PDUs, il faut cependant construire ces PDUs, ces fonctionnalités ne sont pas dans le noyau.
Les informaticiens ont cherché à renforcer l’abstraction réseau offerte par l’interface programmatique socket en créant tout d’abord le concept de procédure distante c’est à dire de fonction qu’on appelle en local mais qui s’exécute à distance: ce sont les RPC (Remote Procedure Call) dont on trouve un standard sous Unix (origine Sun) et un autre sous Windows (incompatible). Dans le même esprit on trouve les RMI en Java (Remote Method Invocation).
En poussant plus loin le concept de RPC, les informaticiens ont développé le concept de méthode distante (au sens méthode de langage objet). Cela a donné lieu à l’architecture d’informatique répartie CORBA (Common Object Broker Achitecture), on invoque une méthode sur un objet quelque part, qu’on sait exister et que l’architecture sait situer. RMI Java et CORBA sont des concepts différents (RMI est plus proche de RPC) et il existe des implémentation CORBA pour Java.
On peut également mentionner (pour la culture générale) l’API réseau définie par le consortium X/Open : The X/Open Transport Interface (XTI). Cette API se veut plus générale que l’API socket BSD (qui est tout de même très connotée TCP/IP), et plus proche conceptuellement du modèle OSI. Mais fonctionnellement, ça fait un peu la même chose. Cette API est disponible sur la plupart des Unix (Linux, Solaris, BSD, etc.), mais est rârement employée dans les programmes. http://en.wikipedia.org/wiki/X/Open_Transport_Interface.
Notons le travail de l’IETF dans le RFC 8303 «On the Usage of Transport Features Provided by IETF Transport Protocols» qui dresse un panorama des différents services fournis par les différents protocoles de transport normalisés à l’IETF (car il n’y a pas que TCP et UDP dans la vie)... Un travail qui aboutira peut être à la définition d’API de programmation réseau plus générique que l’API socket actuelle.
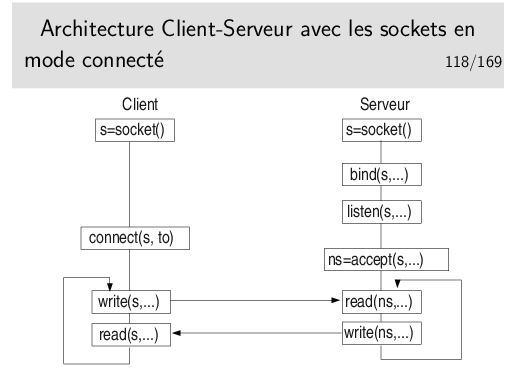
Remarque: pas de bind() coté client, ce n’est pas utile. Lors du connect() le système attribuera une adresse à la socket. Il n’es pas cependant pas interdit de faire un bind().
Communication: le client écrit sur la socket, le serveur lit la socket... Ou l’inverse. C’est au programmeur de décider qui parle le premier. C’est au programmeur d’écrire le dialogue, mais ce n’est pas un dialogue de pièce de théâtre ou de film, il s’agit d’un protocole applicatif (et c’est moins drôle).
Permet d’obtenir un point d’accès aux couches protocolaires de communication désirées
Le préfixe PF (Protocol Family) du paramètre domain peut être remplacé par le préfixe AF (Address Family) lorsque l’on définit l’addresse de la socket (notons que ce sont ces macros ont les mêmes valeurs numériques dans AF et dans PF).
Le type SOCK_DGRAM indique que le mode de communication sera sans connexion, et que les messages seront des datagrammes.
Le type SOCK_STREAM indique un mode de communication orienté flot d’octet, avec connexion.
Le type SOCK_RAW indique que l’on court-circuite la couche immédiatement inférieure.
Le champ protocole est la plupart du temps mis à 0 car il est implicite, PF_INET et SOCK_STREAM impliquent TCP, PF_INET et SOCK_DGRAM impliquent UDP.
On peut cependant utiliser IPPROTO_TCP ou IPPROTO_UDP pour être explicite (il faut inclure <netinet/in.h>).
Informations complémentaires sous linux: man 7 ip, et man 7 ipv6
La valeur rendue par socket() est un descripteur de fichier (sous Unix/Linux) et un type SOCKET sous Windows.

La socket est ouverte en PF_INET (IPv4), sa structure d’adresse sera de type struct sockaddr_in. Pour de l’IPv6 on aurait PF_INET6 et sockaddr_in6.
La fonction bind() n’est pas réservée aux protocoles de la famille IP, elle peut être utilisée avec d’autres. Sa spécification indique que le second paramètre est de type struct sockaddr *. En IP nous devons utiliser le type struct sockadr_in ou sockaddr_in6. Le compilateur ne sera pas content et nous donnera une alerte (un Warning s’il parle anglais). Pour contenter le compilateur on fait un forçage de type (un «cast» en anglais).
Cette structure contient trois champs. Le premier, sin_family doit contenir AF_INET pour IPv4. Pour IPv6, le champ sin6_family contient AF_INET6.
Le second contient l’adresse IP à laquelle on associe la socket. Les connexions devront être adressées à cette adresse particulière. Ce point pose problème. En effet, on doit placer ici une adresse d’une des interfaces de la machine, or il peut en exister plusieurs (il en existe en général au moins deux, une adresse associée à l’interface physique et une adresse de boucle locale, 127.0.0.1). De plus, en IPv6 on a potentiellement plusieurs adresses pour une interface: une adresse qui a un scope de niveau lien (i.e. valable que sur le bus Ethernet), et un scope de niveau global (i.e. valable à travers le grand Internet).
Quelle adresse doit on indiquer ici ? Si on prend une des adresses de la machine, seuls les paquets à destination de l’interface portant cette adresse exacte seront reçus par cette socket et pas les autres. Par ailleurs, il n’est pas portable de fixer en dur dans le programme une adresse à la socket (mais on peut passer cette adresse dynamiquement par argument au programme par exemple).
Pour passer outre tous ces problèmes on peut utiliser la «méta-adresse», appelée adresse joker. C’est l’adresse INADDR_ANY en IPv4 (en fait 0.0.0.0), ou bien IN6ADDR_ANY_INIT (en fait ::) . Une socket «bindée» sur cette adresse acceptera toutes les connexions (en TCP) ou tous les messages (en UDP).
Le dernier membre important de la structure d’adresse est le numéro de port (TCP ou UDP). Remarquez ici, qu’il est indiqué via la fonction htons() pour l’indiquer dans un format «réseau» indépendant de l’architecture matérielle de la machine (problème des architectures big endian versus little endian, voir plus loin).
On ne peut pas attribuer un port déjà attribué.
Sous Unix/Linux, un utilisateur normal ne peut pas attribuer un port inférieur à 1024. Seul l’administrateur peut le faire (l’utilisateur root).

La structure sockaddr_in est ici résumée à l’essentiel, voir sa définition complète dans /usr/include/netinet/in.h sous Unix/Linux (le champ sin_family y est défini, de manière complexe, via une macro, nous l’avons «traduit en clair» ci-dessus).
On remarquera que son champ sin_addr est en fait une structure ne contenant qu’un seul membre: s_addr qui est en fait un entier 32 bits non signé.

Là aussi, la structure sockaddr_in6 est ici résumée à l’essentiel. Consultez le man ipv6 pour plus de détails.
On retrouve les mêmes champs que pour la structure sockaddr_in, excepté le champ sin6_flowinfo maintenant obsolète et laissé à 0, ainsi que le champ sin6_scope_id qui n’a d’intérêt que pour les les adresses locales de lien et qui est fréquemment laissé à 0.
Notez toute fois un problème de taille: la structure d’adresse générique sockaddr prend généralement 16 octets (comme la structure IPv4 sockaddr_in), alors que la la structure d’adresse IPv6 sockaddr_in6 en consomme 28... Tant que l’on se passe des pointeurs, ce n’est pas un problème. Cependant, lorsque l’on veut stocker une adresse, on a un souci. Ainsi la norme POSIX a introduit une nouvelle structure: sockaddr_storage, qui peut donc être utilisée pour stocker indifféremment des adresses IPv4, IPv6, de socket Unix, etc.

La structure d’adresse d’une socket Unix. (Ne pas oublier qu’il n’y a pas que des socket réseau dans la vie!)
Le sun_path est le nom du fichier spécial de type socket, qui est créé dans l’espace de fichier de la machine (c’est un vrai nom de fichier, avec un propriétaire, des permissions, une date, mais pas de taille!). Dans certains cas, on peut avoir des sockets anonymes, c’est à dire sans nom explicite (typiquement lors de l’utilisation de socketpair()).
Le paramètre backlog ne limite pas le nombre de communications simultanées, il limite le nombre de requêtes simultanées. Si n requêtes arrivent au même instant elles seront servies les unes après les autres, dans un temps de service non nul. Si n < backlog, tout va bien, toutes seront servies. Si n > backlog, alors seulement backlog requêtes seront servies.
Si n requêtes arrivent (n > backlog) dans un intervalle de temps bien supérieur au temps de traitement d’une requête, la file d’attente ne se remplira pas complètement et le système aura le temps de traiter toutes les requêtes.
La question principale après ce discours est de savoir ce qu’il est bon d’indiquer comme valeur et existe-t’il une règle pour déterminer celle-ci?
La réponse est: «euh !...»
...Donc, si vous pensez que votre serveur sera très sollicité vous mettrez 20, sinon vous mettrez 5 et vous testerez... (Notez que Linux utilise un minimum de 3.)
En toute rigueur on peut distinguer deux files d’attente: l’une pour le nombre de demandes de connexions incomplètes (TCP n’a pas terminé sa poignée de main en trois coups), et l’autre pour le nombre de demandes de connexions établies. C’est le cas dans les implémentations dans Linux, BSD et quelques autres OS. Dans ce cas, la file d’attente des connexions incomplètes (dont le comportement dépend en fait de l’état du réseau) est paramétrée par l’administrateur du système (p.ex. /proc/sys/net/ipv4/tcp_max_syn_backlog). Par contre, la file d’attente des connexions établies, et donc en attente que le programme les prennent par un accept(), dépend du programmeur qui paramètre la taille avec le backlog.
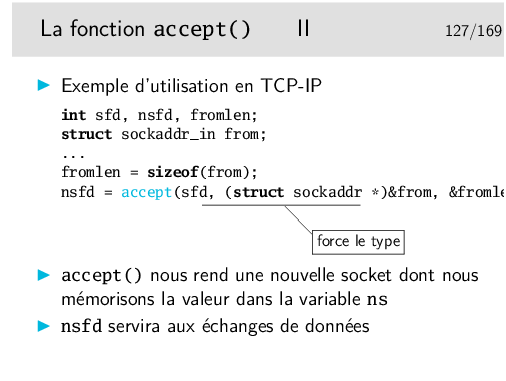
Cette fonction est bloquante, c’est à dire que le processus d’exécution du programme contenant l’appel accept() va bloquer sur cet appel. Le déblocage interviendra lorsqu’une requête de connexion sera reçue.
Il est possible de faire en sorte que accept() ne soit pas bloquant en agissant sur la socket via l’appel système (une fonction du système d’exploitation) fcntl() sous Unix/linux. Dans ce cas, le accept() ne bloque pas et retourne immédiatement. S’il n’y a pas de requête à traiter, la valeur rendue est -1 comme en cas d’erreur. Il faut alors examiner la variable externe errno pour vérifier s’il s’agit vraiment d’une erreur, s’il s’agit simplement du fait qu’il n’y a pas d’appel, errno vaudra la valeur EAGAIN ou EWOULDBLOCK (valeurs identiques en fait).
On ne peut accepter que sur une seule socket.

Dans l’exemple ci-dessus, on récupère l’identité de l’appelant dans la structure from. On pourra connaître ainsi l’adresse IP de la machine appelante et le numéro de port de l’application cliente.
Dans l’architecture que nous donnons du client, on voit que nous ne faisons pas de bind() pour affecter une adresse à la socket. Or, si on travaille en TCP par exemple, on sait que le client doit être identifié par un port. Il faudrait donc en toute rigueur faire un bind(). On préfère laisser cette affaire au noyau du système d’exploitation. Lors du connect(), le système voit que la socket n’est pas liées (binded) à une adresse, alors il le fait, il attribue un port. Cela a l’immense avantage d’attribuer un port libre. Si nous faisions un bind() explicite il y a de forte chances qu’il faudrait de multiples tentatives avant un succès (on ne pas attribuer un port non libre).

Ce n’est qu’un exemple... Mais il marche. Et les structures à manipuler sont complexes... Faites donc comme tout le monde... Copiez/Collez (le man getaddrinfo) et adaptez ensuite à votre cas.
Ligne 4: Tornade blanche sur la structure hints de type struct socakadr. On nettoie son contenu en y mettant des «0» (voir le manuel de référence pour memset()).
Ligne 5: La structure hints paramètre la demande que l’on fait à la fonction getaddrinfo() utilisée juste après (qui effectue la résolution des noms de machine et de port). La valeur AF_UNSPEC indique que l’on veut aussi bien de l’IPv4 que de l’IPv6.
Ligne 6: La valeur SOCK_STREAM, que ce soit en IPv4 ou en IPv6, c’est offert par le protocole TCP. A priori on veut donc une socket TCP...
Ligne 7: Si l’on voulait forcer un autre protocole (à supposer qu’un autre soit possible), on le préciserait ici. Bon, on laisse 0.
Ligne 8: Éventuellement on pourrait préciser notre demande. Voir le man getaddrinfo.
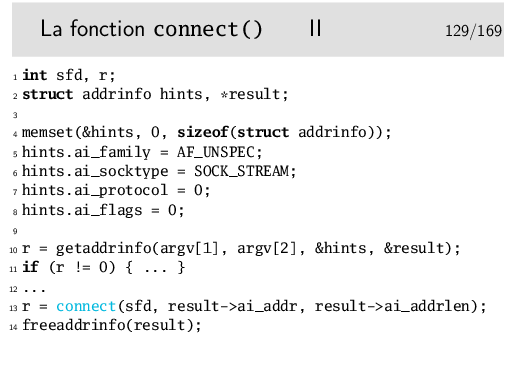
Ligne 10: On récupère l’adresse IP du serveur sur lequel on veut se connecter. Le paramètre argv[1] correspond au premier argument de la ligne de commande qui sert à lancer le programme. On peut utiliser un autre paramètre, de toute manière ce sera ne chaîne de caractères du type «www.quelquepart.com», «192.108.117.241» (IPv4), ou «2001:660:7302:2::11» (IPv6). L’adresse IP, sous forme numérique, sera accessible via le pointeur result rempli par la fonction getaddrinfo(). Le second paramètre argv[2] devra être une chaîne de caractère décrivant le service (ou numéro de port), par exemple «80» ou «http».
En fait, cette fonction getaddrinfo() nous retourne une liste de structures d’adresses possibles: une machine (ici le serveur) peut avoir plusieurs adresse tant en IPv4 qu’en IPv6. Idéalement, il faudrait donc parcourir cette liste et les essayez les unes après les autres.
Ligne 13: Et hop, on se connecte en utilisant la structure d’adresse retournée par getaddrinfo(). (Attention: dans cet exemple on utilise la première adresse retournée, potentiellement il y en a plusieurs à essayer.)
Ligne 14: On libère la mémoire occupée par la liste chaînée result créée par getaddrinfo().

En Unix/Linux les sockets sont des «file descriptors», des descripteurs de fichiers. Un descripteur de fichier est normalement obtenu via la fonction open() qui «ouvre» un fichier. Le descripteur sert ensuite de référence au fichier ouvert dans les fonctions de lecture et d’écriture que sont read() et write().
La socket est donc un descripteur, le réseau (plus exactement le point d’accès au réseau qu’on se crée en créant la socket) est donc assimilé à un fichier. Lorsque la socket est connectée (coté client) ou lorsqu’une acceptation a eu lieu (coté serveur) il suffit d’écrire sur la socket pour envoyer des données et de la lire pour en recevoir.
Le premier argument de ces deux fonctions (ce sont des «appels systèmes») est le descripteur du fichier précédemment ouvert. Pour nous c’est donc la socket. Le second un un tampon mémoire (un «buffer» dans notre jargon) qui contient les octets à écrire (pour write()) ou qui va contenir les octets lus (pour read()). Le troisième argument est la longueur maximale que l’on écrira (pour write()) ou qu’on lira (pour read()).
Par défaut write() tente d’envoyer le nombre d’octets qu’on lui indique dans son troisième argument. Avec les sockets en mode connecté il se peut que le protocole mette en œuvre des mécanismes de contrôle de flux qui bloquent la transmission si le récepteur ne peut traiter les octets reçus au rythme soutenu auquel il les reçoit... C’est, par exemple, le cas de TCP. Si le protocole sous-jacent bloque la transmission avant que le nombre d’octets soumis par write() ne soit réellement envoyé, alors write() va bloquer.
Par défaut, avec les sockets, read() bloque tant qu’on ne reçoit pas de données. Plus exactement read() bloque tant que la couche protocolaire sous-jacente ne nous remet pas les données qu’elle a reçu. Lorsque read() débloque on retrouve les données reçues dans le tampon dont l’adresse constitue le deuxième argument.
Il est possible avec fcntl() de rendre les sockets non bloquantes.

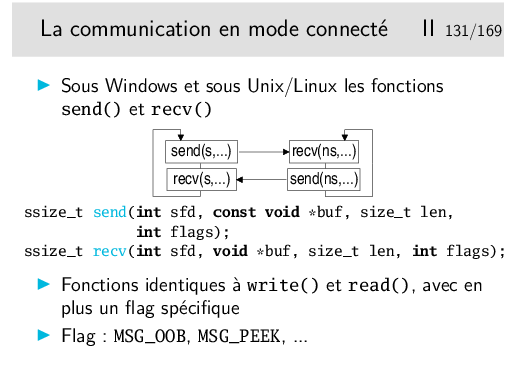
Ces fonctions ont le même comportement que read() et write(). Le flag permet de préciser des spécificités réseau, ce que ne permettent pas les fonctions read() et write().
Le flag MSG_OOB est utilisé pour l’envoi de données urgentes en TCP. OOB signifie «Out Of Band», en français: «données hors bande». Les données ainsi envoyées en TCP ne sont nullement «hors bande», cette notion n’existant pas en TCP, mais elles sont «urgentes» (TCP connaît cette fonctionnalité).
Pour les recevoir il faut utiliser un recv() muni du même flag. A noter que ce n’est pas si simple, il faut que le processus récepteur ait averti le noyau du système d’exploitation qu’il s’attend à recevoir ce type de données urgentes. Lorsque ces données arriveront, alors il recevra un signal (une sorte d’interruption logicielle) qui lui commandera de se dérouter vers une routine de traitement dans laquelle il fera le recv().
Compliqué, non? Rassurez vous (?) nous reverrons cela plus loin.
Le flag MSG_PEEK, en lecture, permet de lire sans que les données soient retirées du tampon de réception. On peut donc les retrouver ensuite avec un nouveau read() ou recv().
Les flags décrits ici sont au standard POSIX. En linux ou Unix de type BSD il en existe d’autres (voir man 2 recv sur ces systèmes).
Sous Windows (bibliothèque winsock-2), les sockets ne sont pas des descripteurs de fichiers mais des types SOCKET. On ne peut dons pas utiliser les fonctions standards du C read() et write().
Notez également les appels systèmes sendmsg() et rcevmsg(), des appels systèmes de plus bas niveau qui permettent de manipuler des vecteurs de buffeurs de message, ainsi que des données auxilières (ou données de contrôle). Vous trouverez dans le man cmsg des exemples rigolos pour récupérer le TTL sur une socket IP, s’échanger des descripteurs de fichiers entre processus via une socket Unix, etc.
D’autre appels système "optimisés" (i.e. selon le concept de zero-copy) peuvent également vous intéresser: sendfile() splice() ...
La manière simple de fermer une socket est d’utiliser close(), il faut être certain qu’il ne reste pas d’octets à recevoir.
On a plus de souplesse avec shutdown(), amis aussi plus de complexité. On peut fermer une socket en écriture (cela provoquera un échange protocolaire sous-jacent avec TCP par exemple (envoi d’un paquet avec le bit de contrôle FIN)) et continuer à pouvoir lire cette socket.
Lorsqu’une socket en mode connecté est fermée, une lecture sur la socket à l’autre extrémité de la connexion renvoie 0 indiquant ainsi la fermeture de la communication (le read() ou recv() renvoie 0). À noter que le renvoi de 0 n’est effectué que lorsque toutes les données encore à lire ont été lues.
Définition sommaire de ce qu’est un processus: un processus est un programme en cours d’exécution dans la mémoire centrale de la machine, dans un environnement donné.
Lorsqu’on exécute un programme, celui-ci est chargé en mémoire centrale, dans un espace qui lui est propre. Dans cet espace il y a le programme lui même ainsi que les structures de données nécessaires à l’exécution ainsi que des informations complémentaires telles que l’identité de l’utilisateur au nom duquel s’exécute le programme. Prenons l’exemple du programme qui réalise l’effacement des fichiers. Lorsque je l’exécute sur mes fichiers, il marche. Si vous l’exécutez sur mes fichiers il ne marche pas (enfin, bon, on espère); Pourtant il ne me connais pas et il ne vous connaît pas. Mais lorsqu’on l’invoque, il est chargé en mémoire pour exécution en notre nom, il est muni de notre identité, ainsi il pourra exécuter les ordres d’effacement en connaissance de cause. Donc un processus, c’est le programme en mémoire plus des informations environnementales.
Un processus possède son propre espace mémoire qu’il ne partage en aucune manière avec les autres processus.
Un thread (en français, un «fil d’exécution», vous comprendrez qu’on ne cherchera plus à traduire le mot) est une sorte de processus à l’intérieur d’un processus. Il peut y avoir plusieurs threads dans un processus. Les threads partagent l’espace mémoire commun du processus. Un thread possède cependant sa propre pile.
Un thread est plus «léger» qu’un processus mais comme il y a partage de mémoire dans un thread il y a risque d’accès simultané en lecture ou en écriture sur une même zone mémoire, donc problèmes d’exclusion mutuelle, problèmes jamais très simples...
Sous Unix/linux, traditionnellement on travaille avec les processus. Toutefois on trouve depuis longtemps une implémentation des threads. Sous Windows il existe les deux nativement et on travaille plutôt avec les threads.
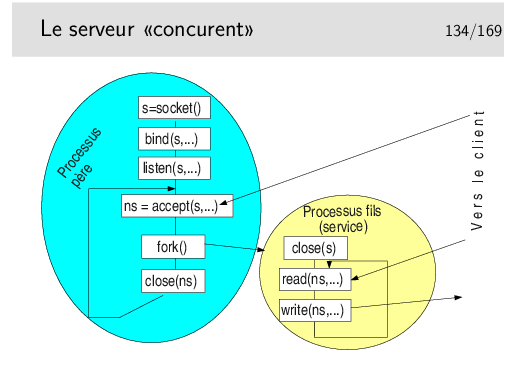
La structure du serveur est presque similaire à ce ce que nous avons déjà vu, à la différence prêt qu’on rajoute après le accept() la fonction de création de processus. Le processus serveur (le père) est dupliqué (on pourrait presque dire cloné) en mémoire. Il est en fait recopié dans une nouvelle zone mémoire et forme ainsi un nouveau processus, dit «processus fils». Comme il est la copie de son père, il exécute le même code. Mais il en va du clonage en informatique comme du clonage en biologie, il existe des mutations génétiques, en tous cas une en ce qui nous concerne en Unix/Linux. Il s’agit du code de retour de la fonction de création de processus: fork(). Dans le processus père, le fork() retourne une valeur différente de 0 (en fait, il s’agit du numéro de processus du fils). Dans le fils, le code retourné vaut 0. Le programmeur d’application peut ainsi dire précisément quel code sera exécuté par le père et quel code sera exécuté par le fils.
Dans notre cas, le fils exécute les fonctions de communication tandis que le père retourne bien vite bloquer sur le accept().
Notez les appels à close() dans le père et dans le fils. Le processus père ferme la socket qu’il a reçu du accept() car il n’en a plus besoin. Cette fermeture dans le père n’a pas d’effet dans le fils. Ce n’est pas une fermeture totale système. La socket ns, reçue du accept() a été dupliquée dans le fils lors de sa création comme tout le code du père. Elle existe donc dans le fils et est active. La fermer dans le père est sans effet dans le fils. Mais pourquoi s’embêter avec cette fermeture ? Un processus ne peut avoir une infinité de descripteurs ouverts, la limite dépend du système d’exploitation, cela peut atteindre 1024 dans les noyaux linux récents. Dans notre cas, à chaque accept() on obtient un nouveau descripteur, donc à chaque nouvelle communication. Si on ne ferme pas le descripteur obtenu dans le père, on ne pourra pas servir plus de 1024 connexion (en réalité un petit peu moins). Et ceci interviendra dans... 3 jours... 3 heures... 3 semaines... Cela dépendra de la charge de notre serveur, et un blocage apparaîtra ainsi, «au bout d’un moment», de manière aléatoire... Allez déboguer cela sereinement...
Dans le fils, on ferme la socket s car elle ne nous sert pas, et «c’est bien» de fermer tout de suite un descripteur devenu inutile.
L’appel système fork() peut échouer si le nombre maximal de processus pour le système est atteint (certains systèmes ne permettent pas de dépasser un certain nombre de processus). L’appel peut aussi échouer s’il n’y a plus assez de mémoire centrale disponible (y compris la mémoire d’échange, le swap sous Unix). Dans tous ces cas, le fork() rend -1 et il faut traiter ce cas d’erreur en fonction du contexte (c’est grave, alors on sort par un exit(), c’est moins grave alors on sort du switch et on continue)

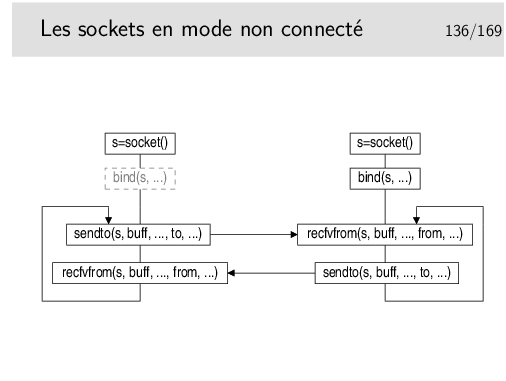
Il n’y a pas de connexion. On ouvre les sockets de part et d’autre, d’un coté, obligatoirement, on affecte une adresse avec bind() (ce sera le «serveur» en quelque sorte), on est alors prêt à recevoir de ce coté et à envoyer de l’autre coté. Le coté qui envoie en premier n’est pas obligé de faire un bind(), le sendto() affectera l’adresse qui convient (le numéro de port en UDP par exemple) si cela n’a pas été fait auparavant.
Le sendto() envoie à l’adresse to.
Le recvfrom() mémorise l’adresse de la socket émettrice dans le paramètre from.
À noter qu’il est possible d’utiliser connect() coté «client», comme en mode connecté. Ce ne sera pas une vraie connexion, en UDP par exemple le protocole ne prévoit rien de ce genre. Donc le connect() sera «virtuel» mais il aura mémorisé un contexte contenant l’adresse de la socket distante et ce contexte sera associé à la socket. Il sera alors possible d’utiliser read()/write() ou recv()/send() pour réaliser l’échange de données.
Les trois premiers arguments de ces fonctions sont semblables à ceux de write() et read(): la socket le tampon mémoire contenant les octets à envoyer (sendto()) ou à recevoir (recvfrom()), la longueur max d’octets à envoyer ou à lire.
Le flag en quatrième argument est très peu utilisé et sera toujours à 0.
L’argument to pour sendto() pointe sur une structure d’adresse contenant l’adresse de la socket distante à laquelle on veut envoyer les données.
L’argument from pour recvfrom() pointe sur une structure d’adresse qui contient l’adresse de la socket qui nous a envoyé les données (dont on peut prendre connaissance au retour de recvfrom()).

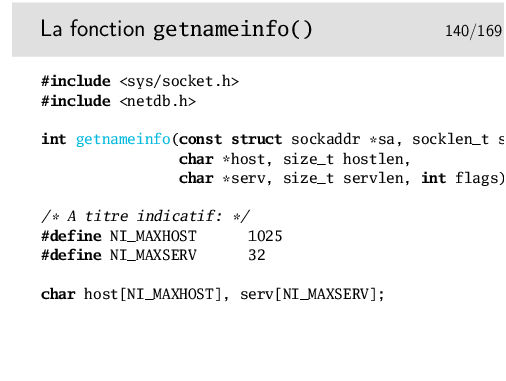
La fonction getnameinfo() permet, par exemple, facilement de récupérer l’identité de la socket distante en lui passant en argument la structure from, argument de accept() ou de recvfrom().
Note: historiquement on utilisait les fonctions gethostbyname() et gethostbyaddr() pour cela (ainsi que gethostbyname2()). Ces fonctions sont maintenant obsolètes (dédiées à IPv4) et ne doivent plus être utilisée dans de nouveaux programmes.

La fonction getaddrinfo() permet de faire la résolution de noms. On lui fournit un nom de node (i.e. un nom de machine) et/ou un nom de service (i.e. un port), et la fonction fait ce qu’il faut pour nous retourner la liste de structure d’adresses correspondantes. (Consulte les fichiers /etc/hosts /etc/services, le système NIS, ou le DNS.)
Notez qu’il est normal pour un nom de machine d’avoir plusieurs adresses, tant IPv4 qu’IPv6. C’est pourquoi cette fonction retroune une liste chaînée res, qu’il faudra prendre soin de vider de la mémoire après usage avec un freeaddrinfo().
En cas de succès, la fonction retourne 0. En cas d’erreur, la fonction retourne un code d’erreur que l’on peut afficher à l’aide de gai_strerror().
La fonction getaddrinfo() attend en paramètre une structure d’adresse hints, qui est en quelque sorte le patron des structures d’adresse que l’on souhaite en retour: on précise si l’on veut des adresse IPv4 ou bien IPv6, ou bien les deux. On peut préciser le protocol utilisé par la suite par la socket (SOCK_STREAM SOCK_DGRAM ou 0). On peut préciser que l’on veut un adresse joker, dans le cas où l’on va utiliser cette socket pour faire une socket serveur. On peut demander des comportement particuliers: par exemple utiliser des adresses IPv4 mappées en IPv6, etc.
Bref, au fil du temps, cette fonction est devenue centrale dans les programmes utilisant des sockets réseau. Si l’on se débrouille bien, il devient facile de coder des programmes qui fonctionnent indifféremment en IPv4 et en IPv6. Le man getaddrinfo() fournit des exemples de code C, qu’il suffit de copier et d’adapter. (Les personnes attentives noteront dans l’exemple en question l’utilisation d’un connect sur une socket UDP.)
La démarche gnérale est la suivante: puisque cette fonction nous retourne une liste de structures d’adresses potentiellements intéressantes, on parcourt cette liste en essayant chaque adresse pour notre socket, en faisant un appel système à socket() puis à bind() (dans le cas d’un serveur) ou à connect() (dans le cas d’un client).
La fonction getnameinfo() retourne sous forme de chaîne de caractères le nom de machine et le service (port) de la structure d’adresse passée en paramètre (typiquement après un accept() ou un recvfrom()).
Le code d’erreur éventuel peut être affiché avec un gai_strerror().

On simplifie ainsi grandement les choses. Les fonctions getxyzinfo() font le travail pour vous, de manière transparente. Une ligne de code (plus le test de réussite) et le tour est joué, même si en fait il faut consulter des services complexes comme le DNS (donc en fait quelques milliers de lignes de codes mises en jeu, de votre coté comme du coté des serveurs, un réseau d’envergure mondiale consulté, etc. Le tout en une seule ligne de code pour vous... magique!)
Les fichiers /etc/gai.conf /etc/nsswitch.conf (ou /etc/host.conf) permet d’indiquer l’ordre dans lequel les sources d’informations seront consultées.
Sous Windows, les mêmes fonctions donnent les mêmes résultats.
Ces fonctions retournent, à l’adresse pointée par leur paramètre name, l’identité de la socket locale pour la première et l’identité de la socket distante pour la seconde. En IP on pourra ainsi récupérer la structure d’adresse struct sockaddr_in de la socket locale ou distante.
La fonction getsockname() peut, par exemple, être utilisée pour récupérer le numéro de port affecté à une connexion coté client, alors qu’on n’a pas fait de bind(). Mais on peut imaginer d’autres utilisations.

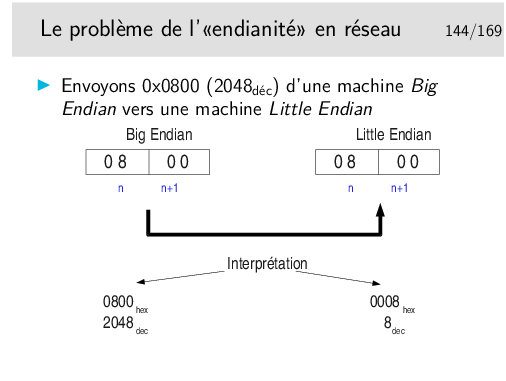
Il est tout à fait naturel de ranger en mémoire les octets dans le sens où ils sont écrits sur le papier. Et lorsqu’on range des octets on commence par l’adresse mémoire la plus faible, donc il est tout à fait naturel de placer le poids fort à l’adresse de poids faible et l’octet de poids faible à suivre. Les gens Big Endian pensent comme cela (Motorola et IBM avec l’architecture PowerPC et donc Apple, Sun avec SPARC et bien d’autres)
Il est tout aussi naturel de penser que le poids faible du nombre tombe tout naturellement dans le poids faible de la mémoire. Les gens Little Endian pensent comme cela (Intel avec l’architecture générique x86 et bien d’autres).
Notez bien que ce problème est dû à l’architecture matérielle et non logicielle. Ainsi, le système d’exploitation unix Solaris de Sun fonctionne sur des machines Big Endian (Sun Sparc) et Little endian (PC type x86 tel que les pentium), donc le même système d’exploitation avec les mêmes outils et bibliothèques de programmation peut fonctionner dans un environnement ou dans un autre et poser des problèmes d’interopérabilité en communication.
Car l’endian a un impact en réseau. Voyez page suivante.

Voyez vous le problème?
Lorsqu’on envoie des octets dans le réseau, on commence l’envoi par l’octet présent à l’adresse de poids faible de la mémoire et on progresse vers les poids forts. Ainsi dans notre exemple, on enverra 08 d’abord et ensuite 00.
Lorsqu’on reçoit, on le fait évidemment dans l’ordre où les données sont émises et on les range en mémoire en commençant par l’octet de poids faible de la mémoire. On recevra donc ici 08 puis 00 et on rangera dans cet ordre.
Tout va bien... Où est le problème? Il est dans l’interprétation que va faire la machine réceptrice. C’est une litttle endian, elle va prendre 00 comme poids fort, elle va donc lire 0008 soit 8 en décimal alors que la machine émission a envoyé 2048 en décimal.
Dans le modèle OSI, le problème évoqué ici est adressé dans la couche 6, la couche «présentation». L’OSI définit un langage permettant de typer l’information et un mécanismes permettant de coder les différents types définis, il s’agit du langage ASN.1 (Abstract Syntax Notation One) et du mécanisme de codage BER (Basic Encoding Rules). Le «modèle Internet» n’intègre pas de solutions pour ce problème. Les développeurs doivent penser à le gérer eux mêmes. Des solutions se voulant standard ont été développées, par exemple la couche XDR (External Data Representation), développée par Sun pour ses Remote Procedure Call sous Unix. RPC/XDR est effectivement devenu un standard, pour Unix, les services NFS et NIS ont été développés avec. Mais ce «standard» n’a pas été suivi par tout le monde et finalement les autres (tel Windows) ont leurs propres solutions.
Des informations plus complète existent sur le réseau: le mot clé «Endian» (attention, pas «indian») vous guidera vers de véritables cours sur le sujet.

Le «s» ou le «l» indiquent une conversion short soit 16 bits ou long soit 32 bits. Pour les ports TCP ou UDP on utilisera par exemple htons() comme dans l’exemple ci-dessus.
Les paramètres et valeurs rendues sont tous de type unsigned
Le read() de gauche bloque tant que l’entité de droite n’enverra pas de données.
Quel est l’impact?
Le programme (on dira le «processus») ainsi bloqué s’arrête, en attente.
Si votre protocole est de type «half duplex», style:
alors il n’y a pas vraiment de problème. Par contre si votre application est plus dynamique et que vous ne pouvez pas prédire quels sera l’ordre dans lequel le dialogue s’établira et s’il sera bien régulier, alors le blocage de la lecture sera un problème.
À noter que dans une application en mode connecté (par TCP par exemple), l’écriture peut aussi être bloquante si les tampons mémoire de réception et d’émission sont pleins (cas où l’application réceptrice ne réussit pas à lire les données au rythme où elles sont reçues).
La fonction accept() est aussi bloquante et on ne peut faire un accept() que sur une seule socket à la fois. Ceci pose un problème si on veut pouvoir gérer plusieurs sockets en mode serveur sur plusieurs ports simultanément.

Quand un descripteur de fichier (une socket est un descripteur de fichier) est positionné en mode non bloquant le read() rend 0 immédiatement (et la variable externe errno est positionnée à la valeur EAGAIN) s’il n’y a rien à lire. Si la lecture est dans une boucle de programme et que l’on revient trop rapidement sur elle alors on sollicite très souvent le noyau du système d’exploitation. La charge CPU monte au détriment des autres applications sur la machine.
Exemple de positionnement de socket en mode non bloquant:

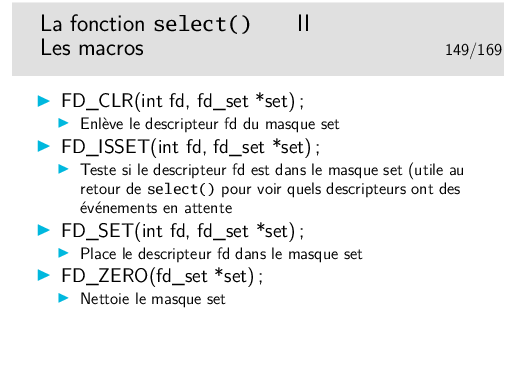
Les masques sont en fait des nombres entiers non signés dans lesquels les rangs des bits à «1» sont significatifs du descripteur: bit 0: descripteur 0, bit 1: descripteur 1, etc.
select() bloque tant qu’un événement n’arrive pas sur un des descripteurs, par exemple si on n’a que le descripteur 1 dans le masque readfs, alors select() bloquera tant qu’il n’y aura pas d’octets à lire sur le fichier correspondant au descripteur 1. La durée du blocage peut être paramétrée par le paramètre timeout. Si celui-ci est à NULL alors le blocage est permanent jusqu’à un des événements attendus sur les descripteurs.
Si on a les descripteurs 1 et 4 dans le masque readfs et que des octets sont à lire sur le descripteur 4 alors select() débloque, mais le masque readfs est modifié, il ne reste plus dedans que le descripteur 4, le 0 est effacé. Il faut tester le masque pour voir quel sont les descripteurs pour lesquels une action est à entreprendre.
Il est possible d’utiliser select() pour gérer plusieurs sockets en mode serveur (état LISTEN si on est en TCP) et attendre ainsi des requêtes de connexion, grâce au masque pour la lecture (readfds ci-dessus).
Le masque exceptfds contient des descripteurs sur lesquels on attend des événements exceptionnels. En pratique, les seuls événements exceptionnels gérables sont les arrivées de données urgentes TCP (nous verrons plus loin une autre méthode pour gérer la réception de ce type de données).
La structure de type timeval contient deux champs tv_sec et tv_usec pour indiquer des secondes et des microsecondes.
l’appel système pselect() propose en plus une gestion des masques de signaux qui pourraient survenir pendant l’attente.
Les appels systèmes poll() et ppoll() font à peu près la même chose, mais avec une api un peu différente...

Ligne 1: on déclare les descripteurs et diverses variables utiles...
Ligne 3: on déclare deux masques, un de référence (r_msq) et un de travail (tr__msq)
Ligne 5: On nettoie le masque de référence
Ligne 6: On place les deux descripteurs dans le masque de référence. Il se peut que les descripteurs soient des sockets ou d’autre canaux de communication comme des tubes. L’exemple est valable quelque soient les descripteurs...
Ligne 7: on détermine quel est le descripteur le plus grand et on mémorise sa valeur dans max.
Ligne 8: on entre dans une boucle sans fin
Ligne 9: on copie le masque de référence dans le masque de travail
Ligne 10: appel à select() (enfin). Le masque de travail est passé dans l’argument indiquant que l’on attend des événements en lecture.
Au retour du select() le masque est modifié, il ne reste dedans que les descripteurs pour lesquels l’événement attendu a eu lieu.
Ligne 11: on teste si fd1 est dans le masque
Ligne 12: si oui, alors on le lit
Lignes 14 et 15: idem pour fd2.
Notez que le masque est modifié. Donc lorsque l’on retourne en début de boucle, on le réinitialise en recopiant dedans le masque de référence (ligne 9).
En toute rigueur il faudrait tester le code de retour de select() pour voir s’il vaut -1 auquel cas il aurait une erreur.

Ligne 1 à 5: la fonction gestionnaire qui sera appelée lors de la réception du signal. On y fait la lecture de la socket.
Ligne 10: on indique au noyau du système d’exploitation que l’on désire recevoir le signal SIGIO (oui, c’est certainement peu évident.... mais...). La fonction getpid() renvoie le numéro du processus courant..
Ligne 11. On indique au processus quelle sera la fonction à appeler lors de la réception du signal SIGIO.
La variable sock doit être ne variable globale (tout bon professeur d’informatique vous dira que c’est mal d’utiliser des variables globales...)

Comme pour les données asynchrones... On ne s’attend pas à recevoir des données urgentes à un instant bien précis, alors on se prépare à les recevoir n’importe quand (voire jamais). On dit au noyau que l’on veut recevoir le signal SIGURG (comme pour SIGIO) avec fcntl(). On indique quelle fonction sera appelée lors de la réception du signal. Lorsque la couche TCP (dans le noyau) recevra une donnée urgente, le noyau enverra le signal au processus qui se déroutera vers la fonction gestionnaire dans laquelle on fera la lecture, via recv() muni du flag idoine.
À l’usage on se rend compte qu’au final il n’y a qu’un seul octet (le dernier du messages hors bande) qui est considéré comme urgent par le récepteur. En effet, TCP définit un mécanisme (pointeur de donnée urgente) qui indique la fin du flux d’octets urgents, mais c’est à l’application de se débrouiller pour définir le début (mais comment ?)...
Le RFC 793 (qui décrit TCP) comporte quelques ambiguïtés sur le sujet. Le RFC 6093 "On the Implementation of the TCP Urgent Mechanism", janvier 2011, rectifit le tir, mais le mal était déjà fait...
C’est ainsi que le pluspart des applications existantes qui utilisent ce mécanisme se contentent de n’envoyer qu’un seul octet urgent (car c’est pris en charge entièrement par la couche transport).
Et le RFC 6093 conclut par «new applications SHOULD NOT employ the TCP urgent mechanism»...

Le niveau SOL_SOCKET permet de paramétrer des options propres à la socket mais parfois celles-ci ont malgré tout une action sur le protocole sous-jacent. C’est par exemple le cas de l’option SO_KEEPALIVE, SO_OOBINLINE, etc.
Les options propres aux protocoles sont décrites dans les pages du manuel telles que tcp(7), unix(7), socket(7).
Remarque: la notation tcp(7) indique que la page du manuel ainsi référencée est située dans la section 7 du manuel de référence Linux. On peut l’appeler par la commande man de la manière suivante: man 7 tcp
SO_REUSEADDR: Deux sockets ne peuvent avoir le même nom (sans quoi le système d’exploitation ne sait pas à quel processus confier les données qui arrivent). Ainsi, si un processus serveur a ouvert une socket sur un port TCP, aucun autre processus de la machine ne peut ouvrir une socket sur ce port. Lorsque le processus serveur se termine, le système d’exploitation va placer sa socket TCP dans l’état TIME_WAIT en attendant que les connections TCP se clôturent proprement (le RFC préconise 4 minutes). Cependant, “on sait bien que” le port n’est plus vraiment utile pendant ce temps là (en général). Un nouveau processus pourrait le réutiliser immédiatement. C’est possible en le demandant gentiment au système d’exploitation avec l’option de socket SO_REUSEADDR.
Autre cas de figure: des récepteurs multicast UDP. Il est normal que plusieurs processus puissent écouter le même canal multicast, et donc d’ouvrir plusieurs sockets UDP sur le même nom (adresse IP du flux multicast + numéro de port). Il faut donc le demander gentiment au système d’exploitation avec l’option de socket SO_REUSEADDR.
SO_KEEPALIVE: considérons une connexion telnet (donc TCP), on peut très bien rester connecté des heures ou des jours sans demander d’échange de données. Dans ce type de connexion silencieuse TCP, il n’y a vraiment pas d’échange, même protocolaire. Si une des applications en communication s’arrête (machine en panne par exemple), l’autre machine ne s’apercevra de rien. Pour cela, un protocole comme TCP prévoit d’envoyer régulièrement des paquets de test (segments vides de données utiles). TCP prévoit de le faire toutes les deux heures si la communication est silencieuse et si l’option en question est positionnée.
Un paquet de test appelle un acquittement, si ce dernier ne vient pas, alors la couche TCP avertit l’application. Dans notre cas il suffit que l’application soit en lecture, le read() ou recv() revient en rendant -1.
SO_LINGER: cette option demande l’argument suivant:
Si SO_LINGER est actif, un close() ou shutdown() sur la socket bloquera tant que les données restant à envoyer (encore présentes dans le tampon d’émission) n’auront pas été correctement envoyées ou que la durée d’attente spécifiée n’aura pas été atteinte. Lors d’une fermeture par exit() (terminaison d’application), l’attente se produit en arrière plan, dans la couche protocolaire.

Voir en ligne http://msdn.microsoft.com/library/default.asp?url=/library/en-us/winsock/winsock/winsock_reference.asp
Exemple de code http://msdn.microsoft.com/library/default.asp?url=/library/en-us/winsock/winsock/complete\_client\_code.asp
Code d’initialisation de la dll winsockk2:

Documentation de référence sur l’ensemble des classes du langage: http://java.sun.com/j2se/1.4.2/docs/api/index.html
Cette documentation peut être téléchargée pour consultation locale via un browser web.

Ligne 8: création de la socket, connexion au serveur indiqué en premier paramètre sur le port précisé en second paramètre. Magique, non? (TCP implicite, cela va de soi).
Ligne 9 et 10: accroche d’un flux d’écriture (out) et d’un flux de lecture (in) à la socket connectée. C’est le seul ennui du mécanisme, les sockets créées ne sont accessibles en lecture et écriture que via des InputStream et des OutputStream.
Exemple extrait de http://java.sun.com/docs/books/tutorial/networking/sockets/readingWriting.html

Facile, ici aussi.
Ligne 3: ouverture de la socket et association au port indiqué en paramètre. Le bind et le listen sont implicites dans cet exemple (il faut savoir que la méthode bind() existe cependant).
Ligne 11: acceptation de connexions. On voit que la méthode accept() rend une nouvelle socket comme pour l’API en C.
Lignes 17 et 18: association de flux d’écriture et de lecture à la socket obtenue par le accept().
Exemple tiré de: http://java.sun.com/docs/books/tutorial/networking/sockets/example-1dot1/KnockKnockServer.java

L’API Socket a été enrichie pour utiliser l’IPv6 (RFC 3493). Tout a était fait que que ce soit transparent pour le programmeur... tout du moins au niveau des sockets. Les soucis viennent des applications qui utilisaient les adresses IPv4 à des choses exotiques, comme identifiant internes par exemple... Comme on passe de 32 bits à 128, ça peut changer beaucoup de choses dans les structures de données.
Quand à la question d’un système double pile vs. IPv4 mappé, la responsabilité se partage entre d’une par l’administrateur qui configure son OS pour addopter l’une ou l’autre des stratégies (sysctl net.ipv6.bindv6only sous Linux), et d’autre part le développeur d’application qui doit savoir se débrouiller avec l’une, l’autre ou les deux stratégies... (Voir la célèbre option de java -Djava.net.preferIPv4Stack=true...) Notez que la stratégie double pile semble prédominer dans les OS d’aujourd’hui.
Une très bonne référence sur le domaine: http://livre.g6.asso.fr/index.php/Programmation_d%27applications

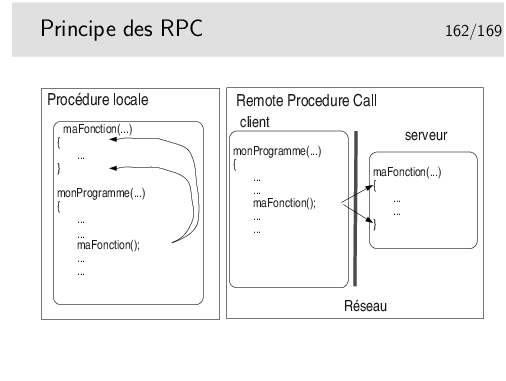
Dans le cas classique, une procédure (en C, une fonction) est appelée en local par le processus en cours. La fonction est interne au processus (interne au programme complet, compilé et l’édition de lien réalisée).
Dans le cas des RPC, le corps de la fonction est externe au programme principal (le client). Il existe cependant une instance locale de la fonction dont le rôle est d’appeler la vraie fonction située dans un processus distinct et même distant (le serveur).
Les aspects «Réseaux» doivent être masqués au programmeur (vœux pieux car si les aspects réseaux sont bien masqués, les mécanismes mis en jeu sont complexes et cette complexité ne peut être totalement rendue transparente).

Il est possible d’utiliser la couche xdr directement au dessus des sockets si on a besoin de transmettre des données structurées contenant des types tels que des entiers ou des réels, afin de ne pas être gêné par les problèmes «d’endianité»...



Faire man rpc et man xdr pour voir toutes les fonctions disponibles pour travailler «à la main» et ruez vous sur rpcgen pour être plus tranquilles (?).
Retenez toutefois que si vous voulez faire des choses sophistiquées vous devrez en passer par ces fonctions..

Un fichier Makefile est aussi produit, on peut donc compiler en utilisant la commande make.
Le fichier ..._xdr.c n’est produit que si nécessaire, que dans les cas ou l’on utilise des types complexes dans le fichier de spécifications.
Le «programme» présenté ici ne comprend qu’une procédure, de nom GETUNAME dans les spécifications. Sous Linux, rpcgen va créer deux instances de cette procédure, une pour le client, appelée getuname_5 et une pour le serveur, de nom getuname_5_svc.
La procédure prend un entier en argument et est censée rendre un type string. En fait la procédure coté serveur et coté client rendra un pointeur de pointeur sur un caractère, donc un pointeur de chaîne de caractères (une chaîne de caractères est déjà un pointeur).
Les RPC renvoient toujours un pointeur, quelque soit le type de résultat.
Le résultat peut être récupéré dans un argument de la fonction client (et renvoyé par un argument de la fonction serveur) en utilisant l’option -M de rpcgen sous Linux (-A sous Solaris). Les codes produits sont alors «thread safe».
Une procédure de nettoyage du résultat est également fournie.
Voyez que les noms donnés à au «programme» et à sa version seront directement utilisables, ils sont définis dans le fichier d’entête.

C’est un peu barbare en première lecture... L’essayer c’est l’adopter (!)
On imagine, dans le scénario ci-dessus que la procédure nous retourne le nom d’un utilisateur de la machine distante si on lui donne en argument le numéro de l’utilisateur. Passons sur la réalisation pratique de cette traduction pour aller directement au point qui nous occupe, à savoir le cas d’erreur. Que se passe-t’il si l’utilisateur n’existe pas. Comment indiquer ce cas. On pourrait rendre la chaîne de caractère NULL par exemple. Mais un utilisateur pourrait s’appeler NULL (des noms, des noms!!!), donc ce n’est pas bon.
On va utiliser un paramètre supplémentaire, appelé ici errno (mais son nom pourrait être autre. Si la procédure est correcte, on renvoie 0 dans ce paramètre et on peut alors lire la réponse, si on renvoie un nombre différent de 0, alors il n’y a pas de réponse (résultat void).
En pratique, on utilise la structure générée par rpcgen dans l’entête xxx.h. Dans la procédure on écrirait:
Ce document a été traduit de LATEX par HEVEA