
F2B002C - Introduction aux RéseauxChristophe LohrAutomne 2018 |
Et bien d’autres...
(Voir D. Comer, W.R. Stevens,...)
Partie I |


Un choc des cultures...
On sait facturer dans un monde, dans l’autre on ne se pose même pas le problème... Mais vient l’heure des comptes... C’est un exemple de différence des cultures, il y en a d’autres, portant sur les principes mêmes du fonctionnement des réseaux: le mode connecté du monde des télécommunications et le mode datagramme du monde de l’informatique (spécialement dans les réseaux locaux et Internet). Nous aborderons ces concepts dans le cours.
Les deux mondes ont eu du mal à coopérer.
L’objectivité qui caractérise les scientifiques cède parfois la place à une «légère» subjectivité...

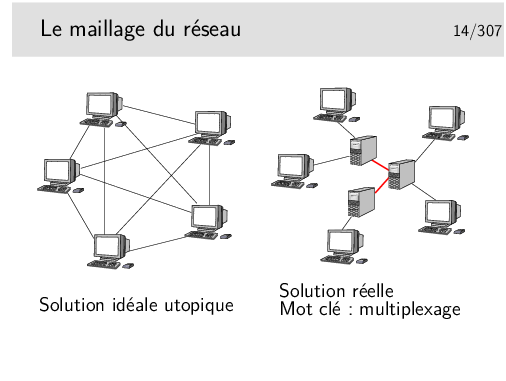
Les terminaux ne peuvent pas être tous interconnectés. Cette solution serait trop coûteuse en nombre de liaisons et ces dernières seraient la plupart du temps sous utilisées.
Les terminaux sont reliés à des machines intermédiaires, des relais, qui concentrent le trafic et acheminent les divers flux d’information sur des supports qui les relient.
Les divers flux de trafic sont acheminés sur les liens inter-noeuds de manière simultanée ou quasi simultanée. On dit qu’ils sont multiplexés et les liens entre les noeuds sont appelés de multiplex. Une des fonction des noeuds est d’assurer le multiplexage des informations sur les liens.
Un multiplex est donc une voie de communication sur laquelle on véhicule plusieurs «communications» à la fois. (notez les guillemets, il reste à définir ce qu’est une «communication», ce n’est pas si simple)

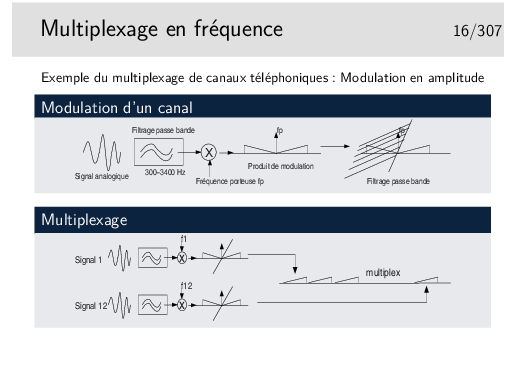
Cas du mutilpexage de canaux téléphoniques:
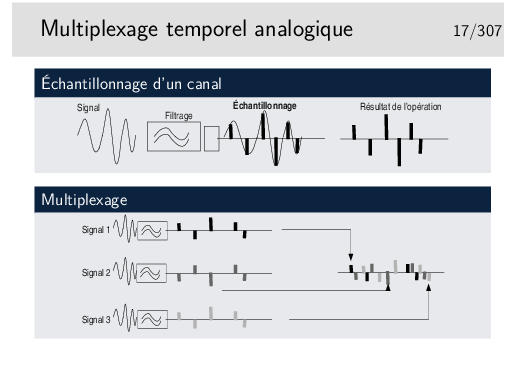
Chaque signal est échantillonné un certain nombre de fois par secondes, chacun avec un décalage dans le temps par rapport aux autres de telle manière qu’ils peuvent être véhiculés sur le même support sans se mélanger après multipexage.
La fréquence d’échantillonnage est telle que le signal doit pouvoir etre reconstitué sans déformations majeures. Shannon a montré que la fréquence d’échantillonnage devait être être le double de la fréquence maximum du signal à échantillonner. Ainsi, en téléphonie, la bande de fréquence est de 300-3400 Hz, on prend 0-4000 Hz par excès, donc la fréquence d’échantillonnage doit être de 8000 Hz.
Le multiplexage par échantillonnage analogique seul ne permet pas de bonnes performances. Le mutiplex ne doit pas être très long, quelques dizaines de centimètres par exemple dans un tout petit autocommutateur téléphonique. Si le support est plus long les échantillons se détériorent à cause des caractéristiques capacitives et selfiques du support, ils sont bruités et déformés et risquent de se mélanger.
La solution réside dans la numérisation.
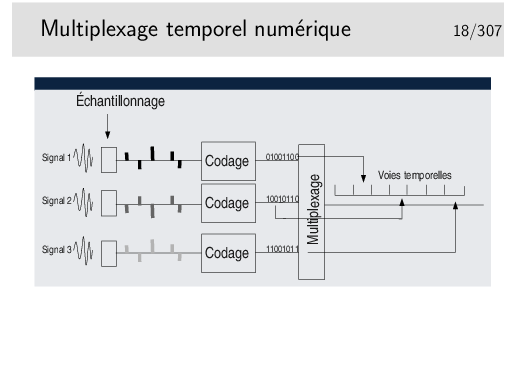
Chaque échantillon est transformé en un nombre binaire pouvant être de 12 bits par exemple, ramenés par des techniques de compression à 8 bits.
En téléphonie par il existe deux techniques principales de codage standardisées par le document ITU-T G711, toutes deux respectent la loi de Shannon édictant qu’il faut échantillonner à 8KHz, donc un échantillon toutes les 125µs. Elles divergent sur les points suivants:
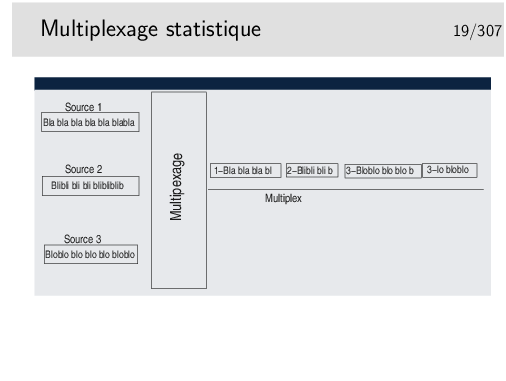
Les données sont découpées en séquences de longueur variable qui sont ensuite injectées sur le même support, les unes à la suite des autres. Il n’y a pas d’ordre à priori. Si une seule source émet elle a toute la bande passante du support à sa disposition. Si n sources émettent simultanément elles disposent chacune de 1/n de la bande passante (si leurs données sont de taille égales).
Les séquences ne doivent pas être trop longues car alors le support est dédié trop longtemps à une seule source.
Les séquences doivent pouvoir être identifiées pour pouvoir les reconnaître à la réception et les remettre à leur bon destinataire. Elles sont munies d’une «étiquette» d’identification qui peut être un numéro de canal ou une adresse de réception.
Le canal est virtuel, il n’existe que si des données sont présentes.
Ce mode de multiplexage est utilisé pour le transfert de données. Il est universellement répandu: ethernet, IP (donc Internet), etc...
Les séquences de données sont appelées «paquets».
Parfois les paquets de données sont de taille constante, on les appelle alors des cellules (réseau de type ATM par exemple) (terme à ne pas confondre avec les cellules des réseaux de téléphonie de type GSM où les cellules sont des zones géographiques desservies par une antenne émettrice/réceptrice).


Pour qu’un signal échantillonné puisse être reconstitué dans de bonnes conditions de restitution il faut qu’il ait été échantillonné à une fréquence deux fois plus élevée que sa fréquence maximale. Ainsi pour un signal de fréquence f, il faut qu’il soit échantillonné à une fréquence 2× f. Intuitivement on comprend qu’on doit au moins prendre un échantillon de chaque alternance (Shannon à montré cela de manière beaucoup plus rigoureuse que la simple intuition).

Questions:
Sur Nyquist: http://www.geocities.com/bioelectrochemistry/nyquist.htm








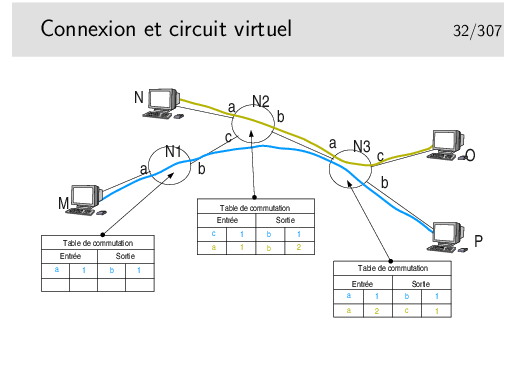
Les paquets issus de M et à destination de P sont munis d’une étiquette 1 en M. Elle reste 1 après passage dans tous les noeuds. Sans doute la communication M-P a-t’elle été établie la première.
Les paquets issus de N à destination de O sont munis d’une étiquette 1. En sortie du premier noeud traversé cette étiquette devient 2 car l’étiquette 1 est déjà attribuée à une communication.
La commutation de circuit virtuel consiste à échanger des étiquettes dans les noeuds et à orienter les unités de données (les paquets) vers les bonnes interfaces de sortie. Le chemin est un chemin d’étiquettes. Celles-ci (les étiquettes) sont réservées lors de l’établissement de la communication.


Relation célérité de la lumière dans le vide (c), fréquence (f) et longueur d’onde (λ): λ f = c
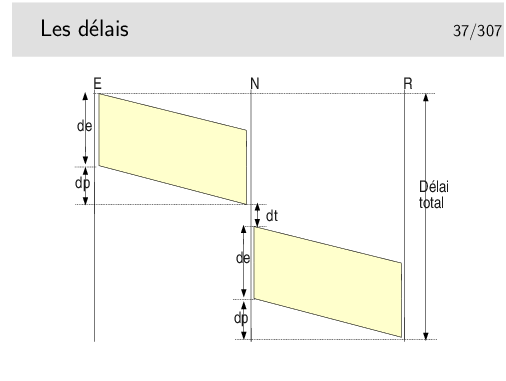
Délai total = 2 de + 2 dp + dt si un seul nœud intermédiaire et si les débits sont les mêmes sur les tous les liens.
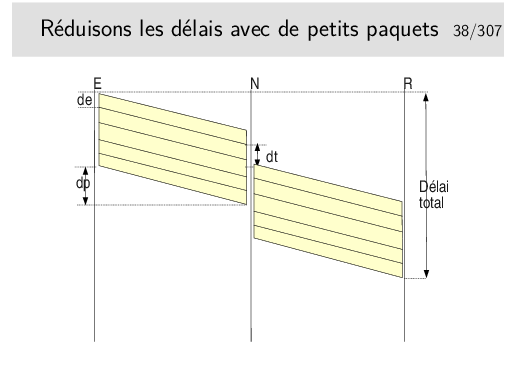
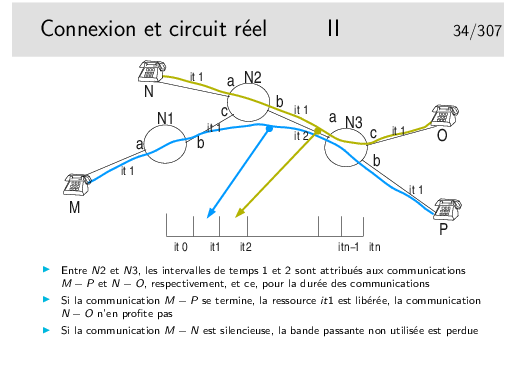
Les interfaces des nœuds fonctionnent en parallèle. Une interface peut recevoir pendant qu’une autre émet. Il reste cependant le temps de traitement, c’est à dire le temps mis par l’unité centrale du nœud pour déterminer vers quelle interface de sortie il faudra acheminer le paquet, plus le temps passé dans les mémoires files d’attente.


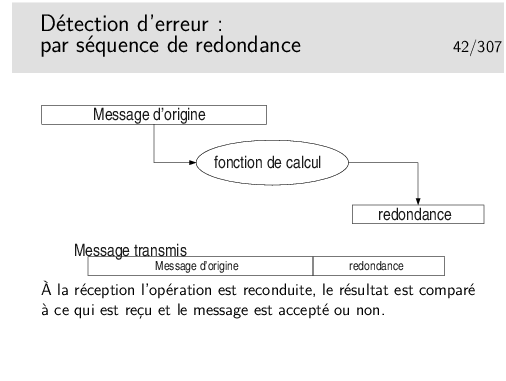
Dans les cas très répandus où les opérations de détection d’erreur sont simples et où les algorithmes ne permettent pas la correction immédiate, on ne peut pas dire si les erreurs de transmission portent sur le message lui même ou la redondance, ou les deux. On jette tout simplement le message (on l’ignore).
On ne se pose pas, à ce stade, le problème de la correction. Ce n’est pas l’affaire de l’algorithme, on s’en remet pour cela à des mécanismes situés dans des couches protocolaires supérieures (si on en a besoin).


Cette méthode est appelée CRC (Cyclical Redundancy Code)

Le reste de la division est appelé CRC du nom de la méthode.

Facile à implémenter matériellement...
Dans l’histoire des télécomunications des réseaux et de l’informatique, un certain nombre de polynôme de CRC ont été standardisés, offrant oist une bonne capacité à détecter les erreurs, soit étant faciles à implémenter (tout est affaire de compromis). Voir .
Existe aussi en solutions logicielles, mais plus le message est long plus il
y a de temps de calcul. Voir les implémentations en C du CRC-32, par
exemple ici:
http://www.cl.cam.ac.uk/Research/SRG/bluebook/21/crc/crc.html
Des fonctions existent toutes faites, par exemple en PHP: int crc32(string str)
voir: http://fr2.php.net/crc32

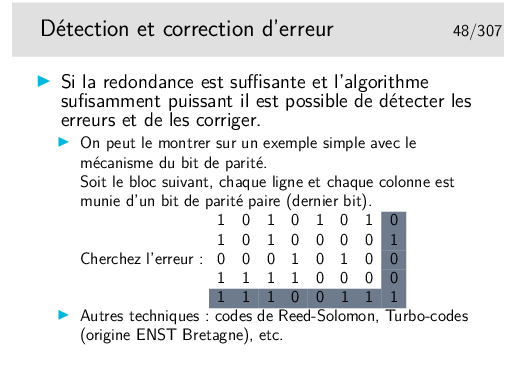
Rappel (s’il en est besoin): si un mot Z vaut 1010, alors son inverse (on dit aussi son complément à 1) vaut 0101 et peut être noté Z (Z barre).

Où comment se créer d’autres problèmes en voulant en régler un... Et maintenant comment on fait pour éviter les doublons ?
C’est une règle, hélas, très générale, en Réseaux, que de se créer de nouveaux problèmes en apportant des solutions à d’autres...
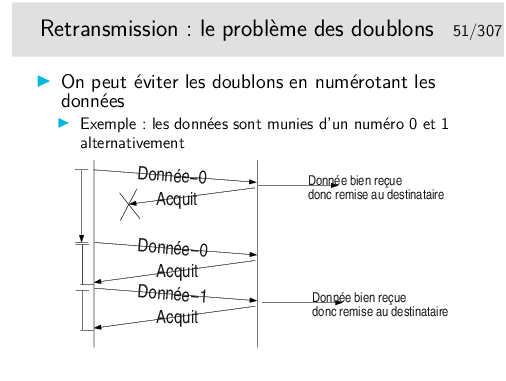
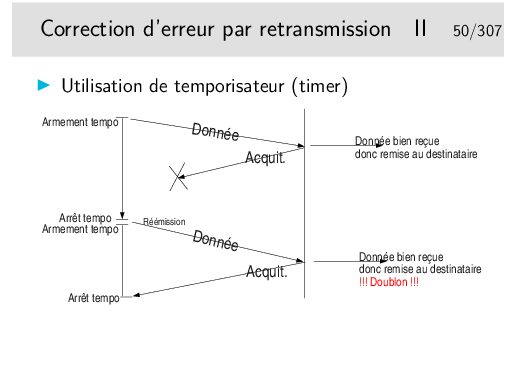
À chaque fois qu’il reçoit un acquittement il pense que celui-ci concerne les données précédemment émises, il vide les tampons mémoires qui les contenaient.
Ainsi, en 4, s’il y a une nouvelle donnée à envoyer ce sera Donnée-0 (pas le même contenu qu’au début du scénario), or le récepteur voyant arriver à nouveau un numéro 0 le rejettera. Le numéro est censé représenter les données, on ne compare pas celle qu’on reçoit avec les précédentes. D’ailleurs celles-ci ont été livrée à l’entité de destination, elles ne sont pas gardées en mémoire.
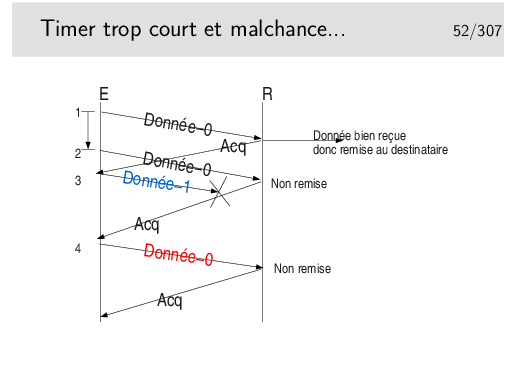
Dans ce scénario le segment Donnée-1 n’est pas reçu mais il est considéré par l’émetteur comme bien reçu. Le segment Donnée-0 suivant est bien émis et bien reçu mais il n’est pas remis à son destinataire final... Tout va mal dans ce scénario!
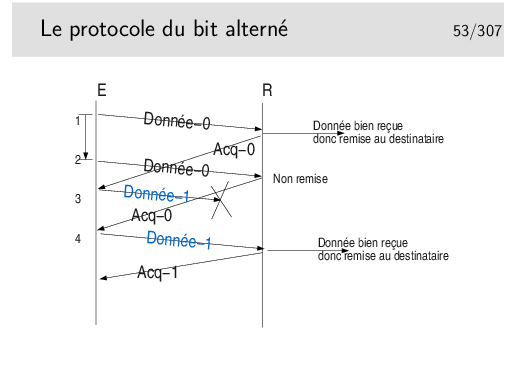
Les acquittements portent les numéro des données qu’ils acquittent. Ainsi, en 4, on reçoit à nouveau Acq-0, alors qu’on attendait Acq-1, il y a un problème, le contenu de Donnée-1 précédent est toujours en mémoire (on ne le vidra que sur réception de Acq-1), on peut donc réémettre Donnée-1 (le même message que précédemment).


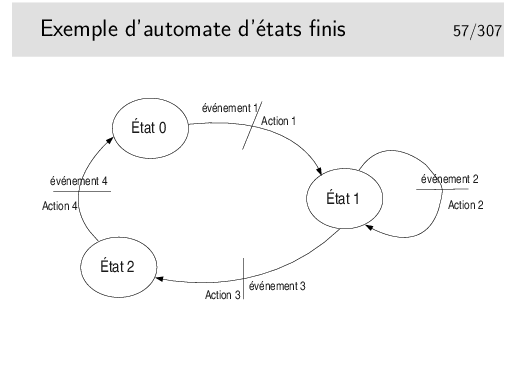
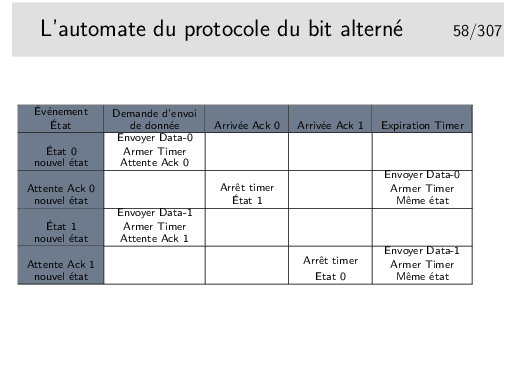
Au départ l’automate est dans un certain état, disons l’état 0 par exemple. Seul l’arrivée de l’événement 1 peut faire que l’automate passe dans l’état 2. Au passage dans ce nouvel état l’action 1 sera effectuée. Un événement ne fait pas toujours changer d’état, on l’illustre ici par l’état 1, dans lequel on reste après que soit survenu l’événement 2 et que l’action 2 ait été effectuée.
Cette représentation est proche de la formalisation mathématique des automates par les «réseaux de Petri».
La représentation schématique est intéressante car elle est souvent plus facile à comprendre (lorsqu’il n’y a pas trop d’états ni d’événements). Cependant elle ne permet pas de s’assurer que tous les cas possibles de relation événement/transition soient envisagés. Il faut alors recourir à la représentation de l’automate sous forme de tableau.

On dit que la fenêtre est «tournante» ou «glissante» selon la représentation qu’on en fait. Voir le transparent suivant.
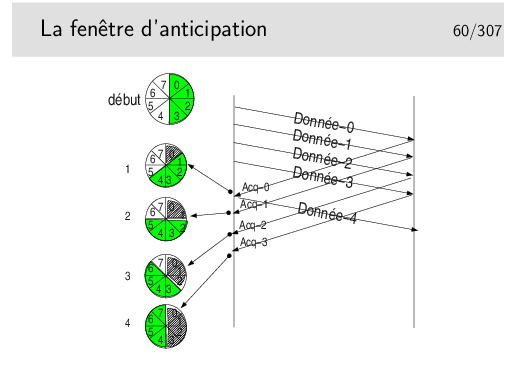
Paramètres: les segments de données sont numérotés modulo 8. La fenêtre d’anticipation est de 4.
On ne peut pas émettre plus de 4 segments à la suite si on ne reçoit pas pendant ce temps un acquittement. Lorsqu’un acquittement arrive, la fenêtre «tourne» d’un pas, le tampon mémoire contenant la donnée correspondant à l’acquittement est libéré, la donnée est considérée comme bien envoyée, on l’efface. En pratique on ne l’efface pas, on considère son emplacement mémoire comme libre. Sur le schéma ci-dessus, on indique cette «libération mémoire» par une zone grisée dans la fenêtre.
Départ: la fenêtre englobe les numéros 0 à 4. On commence l’envoi. L’acquittement pour la donnée 0 arrive en 1. La fenêtre tourne et englobe 1 à 4. Le segment 4 devient éligible à l’émission. Il est émis si une donnée est à émettre. Le tampon mémoire contenant Donnée-0 est effacé. En 2 l’acquittement pour Donnée-1 arrive, la fenêtre tourne et englobe maintenant 2 à 5. Etc.
Un émetteur et un récepteurs ne fonctionnent pas obligatoirement à la même vitesse (au même débit). Les tampons mémoire de réception se vident lorsque les applications destinatrices viennent y puiser les données reçues. Si la machine de réception est lente, si l’application réceptrice prend trop de temps à traiter les données et ne vient pas les retirer suffisamment rapidement des tampons de réception, ceux-ci se remplissent dangereusement. Lorsque les tampons sont pleins les données à recevoir seront perdues. Le contrôle de flux permet d’éviter ces pertes en évitant que les données ne soient envoyées.
Le contrôle de flux pourra être couplé à des mécanismes d’acquittement, ce sont les trames RR et RNR du protocole HDLC-LAPB que nous verrons plus loin : RR pour Receiver Ready ou encore «tout va bien, envoyez !», RNR pour Receiver Not Ready ou encore «OK, j’ai bien reçu vos données mais arrêtez vous quelque temps».



La Poste offre un SERVICE
On accède à ce service par des moyens appelés, en terme «réseaux», des PRIMITIVES DE SERVICE.
On interagit avec le service via les primitives de service dont le paramètre principal est une sorte d’adresse: l’adresse où est situé le bâtiment de La Poste pour aller «poster» sa lettre, l’adresse du destinataire de la lettre pour que le postier sache dans quelle boite aux lettres déposer celle-ci. Cette sorte d’adresse est appelée en termes réseaux le POINT D’ACCÈS AU SERVICE (le Service Access Point ou SAP).
Notion de couche, d’interface entre couches et d’indépendance entre couche.

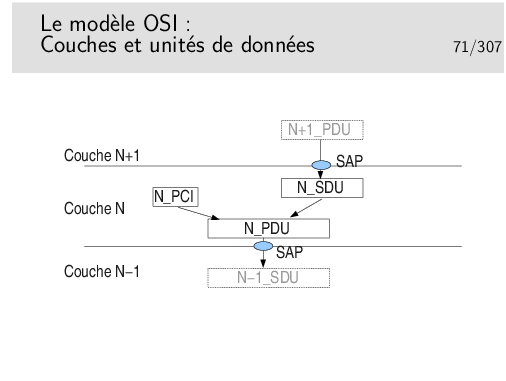
L’unité de donnée fournie par l’utilisateur est une unité de donnée à SERVIR. C’est une UNITE de DONNEE de SERVICE: une SERVICE DATA UNIT (SDU) en anglais.
La couche assurant le service utilise un certain mécanisme qui lui est propre, un protocole particulier, nécessitant un échange de données spécifiques. Ces données protocolaires n’ont rien à voir avec les données utiles, elles servent à la gestion du transfert de celles-ci.
Les données protocolaires (Protocol Control Information) sont ajoutées au segment de données utiles (les données de service, la SDU) pour former une nouvelle unité: l’unité de données de protocole ou PROTOCOL DATA UNIT (PDU).

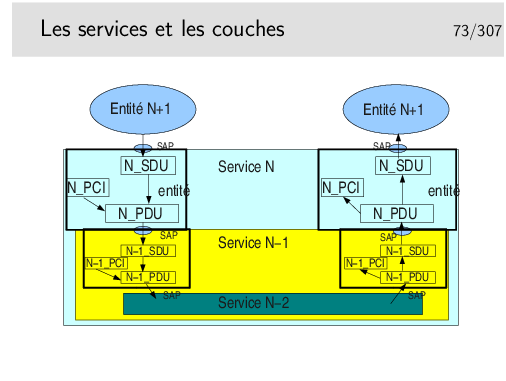
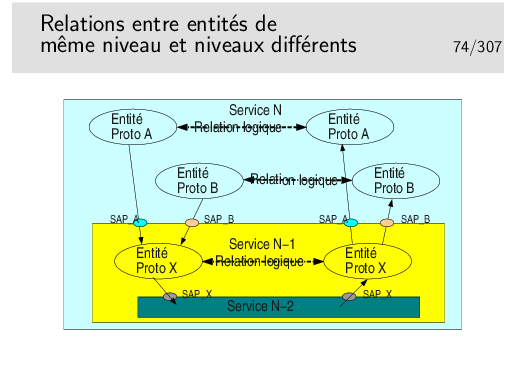
La figure ci-dessus est un exemple de ce qui est possible. Un service N met en œuvre deux types de protocoles différents pour assurer un service. Les entités protocolaires A peuvent communiquer entre elles. De même pour les entités protocolaires B. Les entités A ne peuvent communiquer avec les entités B car elles ne «parlent pas» le même langage (le même protocole).
Il est possible que les entités A et les entités B utilisent le même protocole X sous jacent (de couche N−1). Lorsque l’entité A de gauche émettra un PDU vers l’entité A de droite, il faudra que ce PDU soit muni de l’identité du SAP entre l’entité A (niveau N) et l’entité X de niveau N−1 (donc SAP A). Sinon l’entité X de droite ne saurait pas vers quelle entité réceptrice A ou B envoyer le PDU. De même pour les entités B.
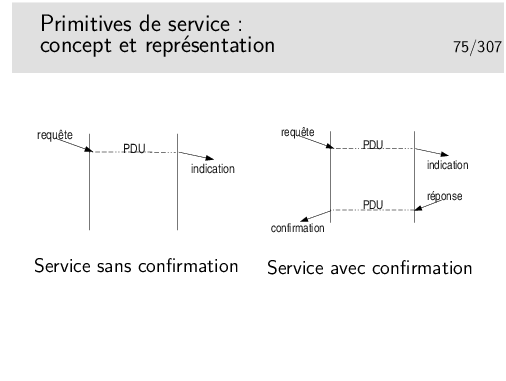
Le concept de primitive de service peut s’apparenter au concept de fonction de programme informatique ou mieux encore d’objet au sens «langage orienté objet» tel C++ ou Java.
Mais nous sommes face à un problème car si les concepts sont voisins, ils n’en ont pas moins des représentations différentes. Les primitives définies pour une couche protocolaire sont indépendantes de tout langage informatique. Fort heureusement d’un coté. Sous un autre angle de vue cela pose problème. En effet, il faut pouvoir, à la fin, implémenter les protocole dans un langage et sur un système d’exploitation. Comment traduire en C/C++ sous Unix/Linux, Windows ou MacOS le paradigme «Requête/indication» présenté ci-dessus ? Il faut noter en outre que la requête peut être codée en C et l’indication en Java.
Dans la pratique, il y a une réelle différence entre les outils à notre disposition pour développer des applications et les définitions formelles des primitives. C’est vrai pour les applications standards, c’est encore plus différent pour les entités protocolaires développées dans les noyaux des systèmes d’exploitation.
Lorsqu’on étudie les documents de spécification d’un protocole on est toutefois confronté au concept de primitive. Il faut alors absolument savoir ce que cela représente, en faisant abstraction, en première lecture, de toute idée d’implémentation. Par la suite peut se poser le problème de l’implémentation.


Niveau physique et niveau liaison: on ne traverse pas le réseau.

Rappel de l’épisode précédent (niveau physique et niveau liaison): on ne traverse pas le réseau !
Épisode présent (niveau 3): on traverse le Réseau !

Tout ceci est très théorique. En pratique, il faut considérer ce niveau transport par type d’architecture: IP, Novell IPX, AppleTalk, IBM SNA, Decnet de Digital (racheté par Compaq, racheté par HP).



Tout ceci est à nouveau très théorique. Il faut le replacer dans le contexte de chaque architecture (IP, IPX, etc.)
La couche application, qu’on «résume», ici, d’une seule phrase est la plus complexe de toutes dans la réalité des recommandations ISO et ITU-T. Même si ses mérites sont grands, sa complexité et le peu d’outils de développements (API) ont fait qu’il n’existe pas beaucoup de réalisations pratiques (courrier électronique X400, annuaire X500 et quelques autres). Ces applications ont vu le jour vers la fin des années 80, à une époque où l’Internet se répandait déjà beaucoup dans les réseaux du monde de l’enseignement et de la recherche. Le début des années 90 a été décisif, après ne courte période d’incertitude, l’ouverture des standards autour de IP, face à au monde OSI plus fermé à fait pencher la balance en faveur de IP.
Aujourd’hui, il reste cependant le modèle, incontournable, tout au moins pour les couches bases. Il nous aide à placer les concepts et les fonctionnalités des différents réseaux qui existent.

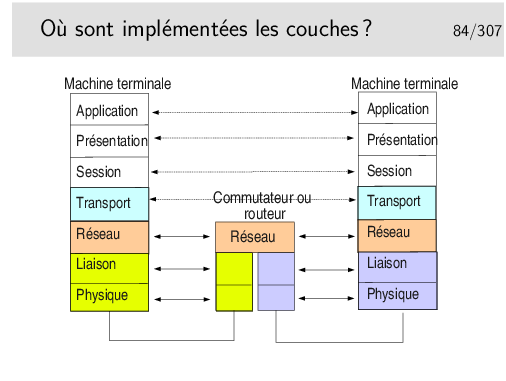
Toutes les couches sont implémentées dans les machines terminales.
Seules les couches 1 à 3 sont nécessaires dans les machines du cœur de réseau.
Il est très important de noter l’indépendance entre les couches. Voyez ici les couches physique et liaison concernant le lien coté gauche et le lien coté droit. Ces niveaux peuvent être totalement différents du point de vue physique mais aussi du point de vue couche liaison. On pourrait avoir, coté gauche un lien Ethernet sur paire torsadée et de l’autre un lien sur fibre optique employant la technologie Sonet/SDH.
Les débits peuvent aussi être différents. On pourrait avoir 1GB/s coté gauche et 155Mb/s coté droit.
Les couches Physique et liaison sont en général implémentées sur un même support matériel, une carte d’interface du type de celle que vous pouvez avoir sur votre ordinateur personnel
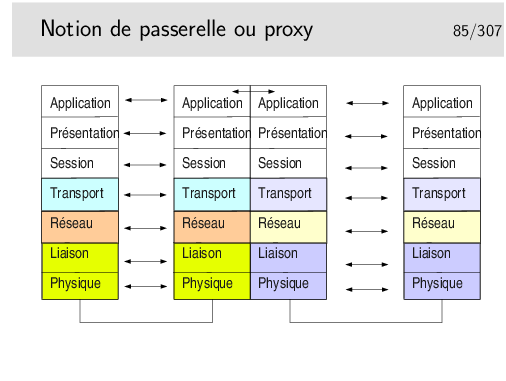
Toutes les couches sont implémentées dans la machine intermédiaires. La couche application réalise une traduction des données pour les adapter à l’application destinatrice. Les protocoles mis en oeuvre à gauche peuvent être tous différents de ceux de droite.
Dans le cas d’un proxy de type Web, les protocoles sont les mêmes à gauche et à droite, mais on oblige toutes les requêtes à passer par l’application intermédiaire (on imagine par exemple un client Web à gauche et un serveur à droite). Cela permet de réaliser des caches permettant de mémoriser les documents déjà téléchargés, afin de les renvoyer plus rapidement sans encombrer le réseau à nouveau.
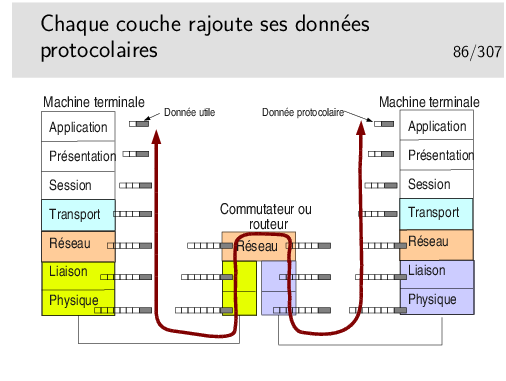
Notion de rendement: rapport entre le volume des données utiles et le volume total de données véhiculées sur un niveau.
Par exemple, pour une application cliente telnet, sur TCP IP sur Ethernet (nous verrons ces protocoles plus loin dans le cours) il est courant d’envoyer les données octet par octet dans le sens client vers serveur (au rythme où sont frappées les touches du clavier). Pour chaque octet envoyé, telnet ne rajoute rien mais TCP (niveau 4) rajoute au moins 20 octets (plus 12 avec les options des implémentations TCP d’aujourd’hui), IP (niveau 3) rajoute 20 octets. On a donc au moins 1 + 20 + 20 = 41 octets et au plus 1 + 20 + 12 + 20 = 53 octets. Dans le cas 41 octets, Ethernet rajoute 5 octets de bourrage pour arriver à la taille minimale requise, donc 46 octets. Par ailleurs Ethernet rajoute 18 octets d’informations protocolaires donc 46 + 18 = 64 octets dans un cas et 53 + 18 = 71 octets dans l’autre.
Le rendement est de 1/64 dans un cas et 1/71 dans l’autre. Ce n’est pas très efficace mais c’est ainsi !







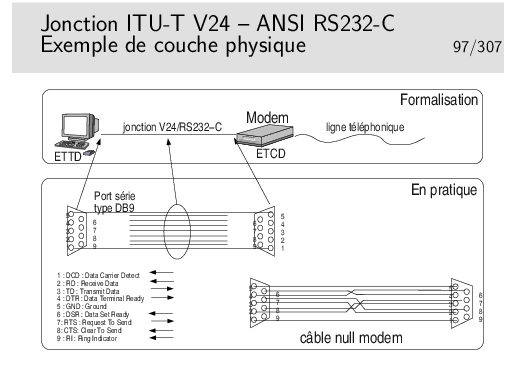
ETTD: Equipement Terminal de Circuit de Données (en anglais DTE: Data terminal Equipment). Désigne le coté terminal de la jonction, en pratique, très souvent, l’ordinateur.
ETCD: Equipement Terminal de Circuit de Données (en anglais DCE: Data Circuit Equipment). Désigne le coté Réseau de la jonction. Souvent en pratique il s’agit du modem. Mais cela peut être aussi une interface série d’une machine.
Ce sont de vieux termes, encore utilisés dans le cas des liaisons de type série, à bas débit.
En pratique votre ordinateur est relié à un modem standard (non ADSL), via le port COM1 ou COM2 (appelés encore «ports série»), par une jonction conforme à la recommandation V24/RS232-C.
Le câble NULL Modem permet de raccorder deux ordinateurs entre eux via leur port série. On dit encore de ce câble qu’il est «croisé» car, en particulier, la broche 2 de l’un est reliée à la broche 3 de l’autre et réciproquement.
Voir: http://www.loop-back.com/null-mod.html
Dans ce type de jonction on trouve les supports pour la transmission de l’information utile mais aussi des supports pour de l’information de service («présence porteuse», «terminal prêt», etc.). Ce type d’information est aussi appelé «signalisation».
Le codage des bits est réalisé par des niveaux de tension. Un seul fil est nécessaire par sens de transmission (plus une «terre» commune, c’est d’ailleurs plutôt un «retour commun» qu’une terre).
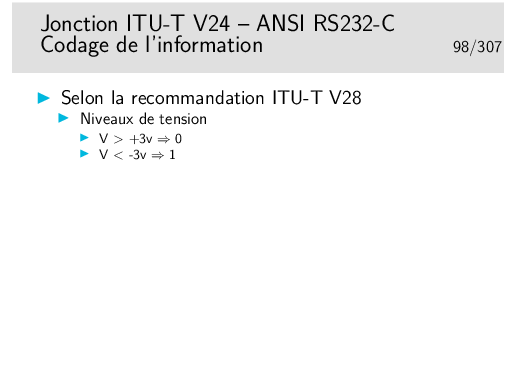
Ceci est un exemple, il en existe d’autres. Le codage par niveau de tension est simple à réaliser mais il est peu performant en termes de distance (quelques dizaines de mètres au plus) et de débit (environ 100Kb/s max).
Pour les plus grandes distances et les plus forts débits on privilégie les niveaux de courants. Pour cela il faut deux fils par jonction (2 fils par signal). Ce mode de codage est plus résistant aux perturbations électromagnétiques.
Les schémas ci-dessus présentent des «1» sous formes d’impulsions positives (crénaux vers le haut), contrairement à la réalité V24/V28 où les «1» sont codés par des tensions négatives.


Une horreur à ne pas dire: «des bauds par seconde!» car alors ce n’est plus un débit mais une accélération.


HDLC: High-level Data Link Control (ne pas trop chercher le sens profond de cet acronyme... Se souvenir cependant fermement de son nom et de ce qu’il représente...).
Le champ adresse est aujourd’hui très mal nommé car ce type de structure de données n’est généralement utilisé que pour des liaisons point-à-point. Donc, ici, l’adresse ne sert pas à l’adressage... Il sert à distinguer des trames de commandes et des trames de réponses. Un trame de commande est une trame émise sans qu’elle soit demandée, l’émetteur décide seul de l’émettre. Une trame de réponse est une trame émise en «réponse» à une trame de commande.
Les protocoles des niveaux supérieurs ne prévoient pas de délimitation de leurs PDUs. Chaque fois qu’on ne sait pas comment faire pour véhiculer de telles unités de données on a recours à HDLC, en le simplifiant parfois. C’est par exemple le cas du protocole PPP (Point to Point Protocol) utilisé pour véhiculer les datagrammes IP sur les liaisons de type série, telles que celle utilisées par les particuliers pour se connecter à Internet via des modems.
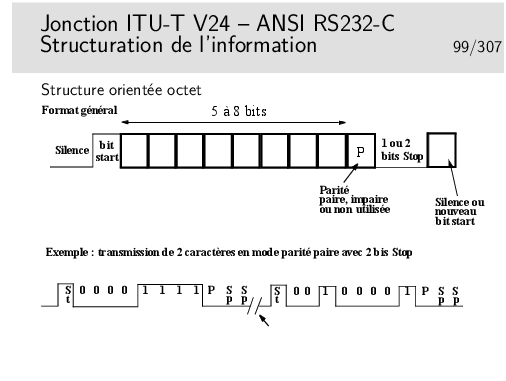
Dans le cas de PPP sur lignes séries de type PC (entre le PC et le modem et ensuite via la modulation du modem) les trames HDLC sont découpées octet par octet et émises en mode asynchrone avec, par octet, un bit START et un ou deux bits STOP (plus, éventuellement, un bit de parité). Le fanion est constitué par l’octet 0x7E, donc comme dans le cas synchrone. Si cet octet se retrouve dans les données, il est remplacé par deux octets.

LAPB signife: «Link Access Protocol, Balanced», ce qui traduit en français donne «protocole d’accès au lien en mode équilibré». En fait il utilise le Asynchronous Balanced Mode (ABM) de HDLC, mode dans lequel il n’y a pas de maître/esclave, les deux parties peuvent accéder indifféremment au lien.
On ne sait pas trop comment ces appellations ont été définies et par quel normalisateur (il ne s’en vante pas celui-là). Ce n’est pas très important... Il est, par contre, très important de savoir que cela existe et se nomme ainsi et aussi comment cela fonctionne, ce que nous allons voir dans ce qui suit.
La numérotation des trames et les acquittements permettent d’utiliser le mécanisme de la fenêtre d’anticipation.
L’utilisation du champ adresse est parfaitement défini dans la recommandation ITU-T X25, le lecteur se référera à ce document pour les détails techniques si nécessaire. Ces détails n’apportent rien de fondamental au concept général, on ne fournira pas, ici, d’explications complémentaires.
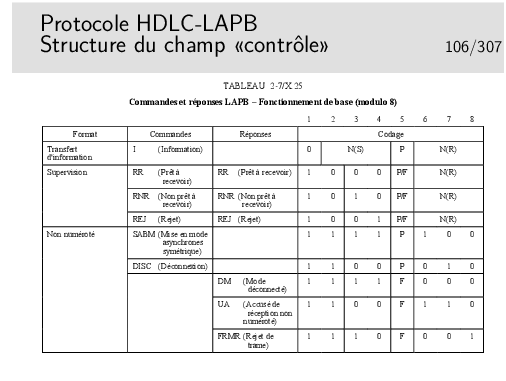
Les trames I sont aussi dites «trames numérotées». Elles sont munies, à cet effet, d’un champ N(S) appelé «numéro de séquence en émission», en pratique c’est le numéro de la trame (ici modulo 8, mais on peut numéroter modulo 128 ou 32768, le champ «contrôle» est alors codé sur 2 ou 4 octets).
Le champ N(R) est appelé «numéro de séquence en réception», en pratique il s’agit de l’acquittement. Pour une valeur x, il signifie: «vous pouvez m’envoyer la trame n∘x».
Le fait que les trames d’informations peuvent porter des acquittements s’appelle «piggy backing»
Les trames de supervision servent à porter uniquement des acquittements et à réaliser la fonction de contrôle de flux:
On ne s’attardera pas ici sur le rôle du bit P/F...
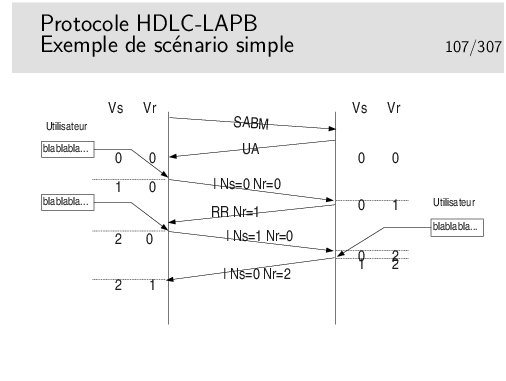
Les entités protocolaires d’extrémités (donc des logiciels qui implémentent le protocole LAPB) sont munies de deux compteurs Vs et Vr. Vs sert à numéroter les trames à émettre, Vr sert à vérifier que les trames que l’on reçoit portent le bon numéro.
Au départ, lors de l’initialisation de la connexion par l’échange SABM/UA, les compteurs sont mis à 0. L’utilisateur coté gauche désire envoyer des données. Celles-ci sont encapsulées dans une trame. Le champ Ns de celle-ci va être rempli par la valeur de Vs, le champ Nr par la valeur de Vr. On recopie tout simplement Vs et Vr dans Ns et Nr. Un fois la trame envoyée on se préparera à envoyer une trame suivante si nécessaire. Celle-ci verra son numéro progresser de 1. On prépare donc cela en faisant progresser Vs de 1. Lors de la seconde émission on recopie Vs et Vr dans Ns et Nr de cette seconde trame, puis on l’émet et on incrémente Vs de 1.
Lorsque le récepteur (droite) reçoit la première trame il vérifie que son numéro de séquence Ns est bon en le comparant avec son compteur Nr. Les deux valeurs étant égales, la trame est acceptée. Le compteur Vr droit progresse de 1, une trame d’acquittement est envoyée avec son Nr = 1 (recopie du Vr).
Plus tard, le coté droit désirera parler à son tour et cet événement surviendra juste au moment de la réception d’une trame (dans notre scénario). Il émettra donc directement une trame I portant le bon Ns et bien sur le bon Nr. (Piggy backing)
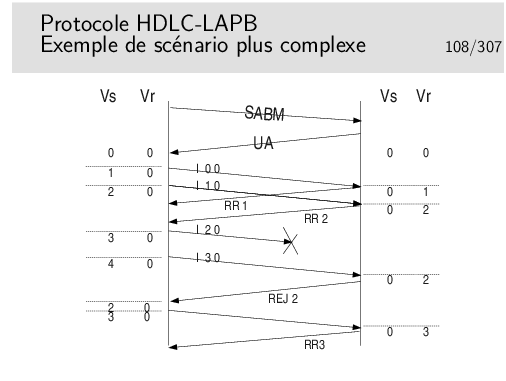
Pour quelle raison la trame numéro 2 (I 2 0) peut-elle ne pas être reçue ?

La recommandation X.25 «suggère» que pour un appel sortant (coté demandeur), l’ETTD choisisse le numéro de voie logique le plus haut disponible. Pour un appel entrant (coté demandé) il est suggéré que l’ETCD choisisse le numéro de voie logique le plus bas disponible.
On rappelle que l’ETTD (Équipement Terminal de Traitement de Données, ou DTE en anglais) est l’équipement «terminal» (l’ordinateur) et que l’ETCD (Équipement terminal de circuit de données, ou DCE en anglais) est l’équipement «réseau» (le commutateur de raccordement).
Le paquet d’appel est muni d’un bloc d’adresse contenant l’adresse de destination et possiblement l’adresse source. Il se comporte dans le réseau comme un datagramme. Il n’y a pas de système de signalisation (protocole pour l’établissement, la rupture et la supervision des communications) comme dans d’autres types de réseau à commutation (téléphone, ATM, Frame Relay, MPLS)
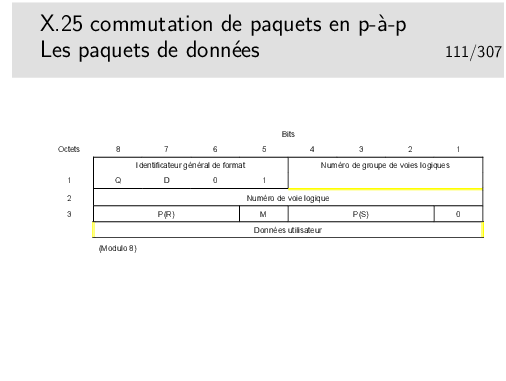
Les paquets de données sont numérotés (champ P(S): numéro de séquence en émission). Ils contiennent aussi un champ P(R) permettant de transporter les acquittements (piggy backing)
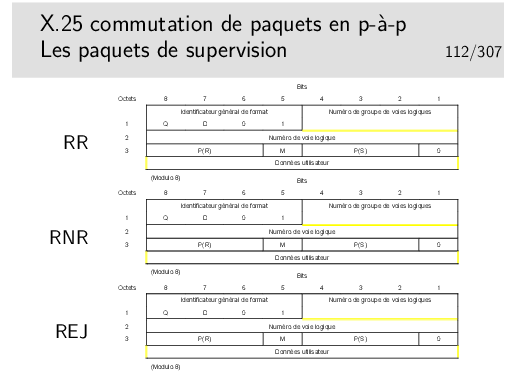
Comme au niveau 2 (LAPB), nous avons des paquets RR (Receiver Ready), RNR (Receiver Not Ready), REJ (Reject) permettant de transporter les acquittements, de réaliser le contrôle de flux et la reprise sur erreur.
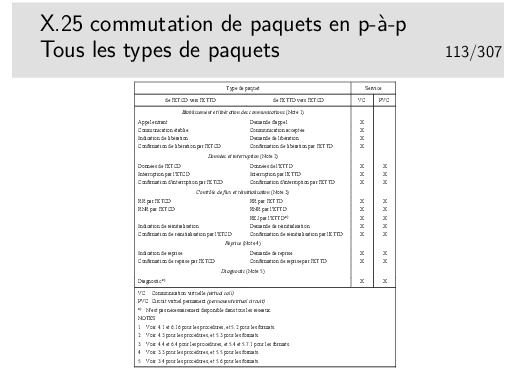
La liste ci-dessus est placée ici pour votre «culture générale», vous n’avez absolument pas besoin de connaître cette liste parfaitement.
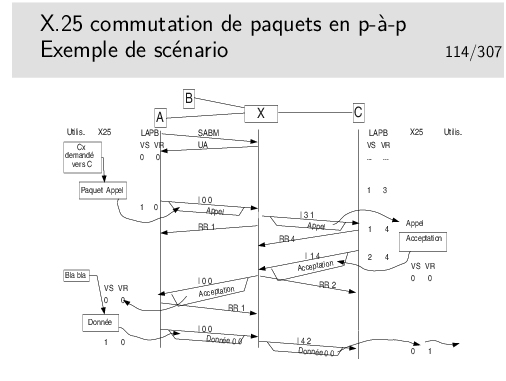
Machines terminales (ETTD): A, B et C.
Commutateur (ETCD): X
On suppose dans ce scénario qu’une communication est déjà établie entre B et C. On ne s’en préoccupe pas mais le niveau 2 X-C est établi pour supporter cette communication. Des trames ont donc déjà été échangées entre X et C. Au moment où nous arrivons, les compteurs Vs et Vr du contexte LAPB en C sont, respectivement à 1 et 3.
Entre A et X, le niveau 2 n’est pas établi au début du scénario.
Partie II |


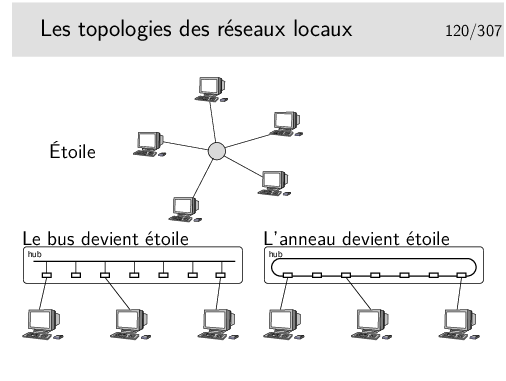
La topologie en étoile repose sur un nœud actif central qui contrôle le «droit de parole» des stations et achemine l’information. Cette structure n’a jamais vraiment été fortement déployée à grande échelle, on peut noter cependant les réseaux locaux basées sur le protocole X25, au début des années 80 et les ceux basés sur la technologie ATM dans les années 90 (mais c’était pour émuler Ethernet, c’est à dire un bus).
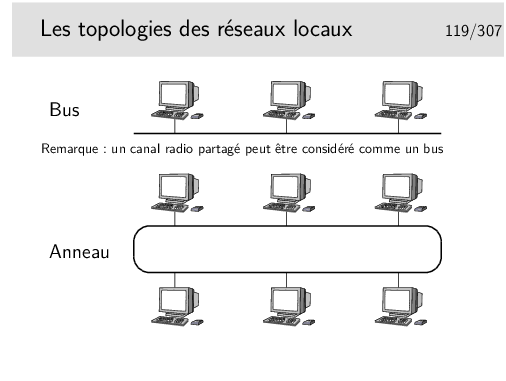
Les topologies à succès sont le bus (Ethernet, qui a gagné la bataille) et l’anneau (Token Ring, d’IBM, en cours d’abandon).
Au cours du temps, le réseau en bus Ethernet a, cependant, évolué vers une structure en étoile, où les nœuds (appelés «hubs») sont des boîtiers électroniques qui émulent un bus. Le «hub» fonctionne comme un bus.
La technologie Token Ring a, elle, été très rapidement implémentée dans des boîtiers électronique renfermant la structure d’anneau.
Aujourd’hui, donc, la topologie est en étoile, mais l’ensemble fonctionne comme un bus (ou encore parfois comme un anneau).




Beaucoup de sous comités:
Note: WiFi (Wireless Fidelity) est une dénomination commerciale pour le 802.11
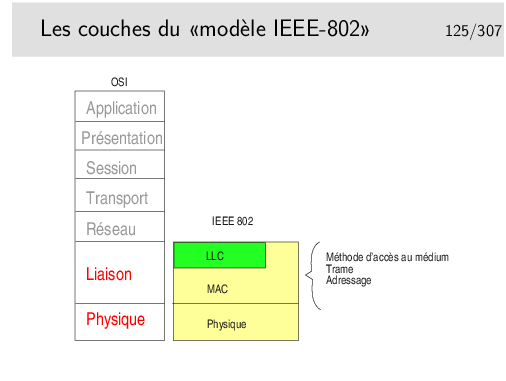
La couche LLC permet de définir différents types de liaisons (avec/sans connexion et avec/sans acquittement). Elle n’est pas toujours obligatoire, en Ethernet elle est optionnelle, certains protocoles de niveau 3 l’utilisent, d’autre pas. Par exemple IP, sur Ethernet, n’emploie pas, par défaut, la couche LLC (mais peut le faire, le choix se fait par paramétrage au niveau du système d’exploitation).
La couche MAC est centrale, elle définit l’algorithme gérant l’accès concurrent au support. Elle définit aussi une structure de trame ainsi qu’un mécanisme d’adressage (les adresses MAC, nous verrons cela plus loin).

Une autre méthode consiste à créer un anneau virtuel. Les stations s’échangent un jeton dans un ordre donné (la station A passe le jeton à la station B qui le passe à C, etc. La station qui désire émettre doit attendre de voir arriver le jeton). Ce type de réseau a été développé par des industriels des mondes de l’automobile et de l’aviation américains. Il fait partie des «réseaux locaux industriels». Il a été standardisé sous le numéro 802.4 par l’IEEE. Il ne s’est pas développé de manière importante.

La technologie WiFi (IEEE-802.11) n’a rien à voir, à priori, avec Ethernet, mais on commence à l’appeler couramment «l’ethernet sans fil», c’est dire... Elle s’adapte, en effet, très bien à Ethernet via des ponts simples à mettre en place.
La technologie Ethernet évolue de manière souple où chaque étape d’évolution ne remet pas en cause les versions antérieures. On peut raccorder une interface 10Mb/s sur une interface 100 ou 1000Mb/s. Les matériels d’interconnexion sont compatibles avec les trois débits.



Quelle est la dimension du réseau (son diamètre ou encore la distance
maximale entre deux stations) si la taille minimale des trames est de 512
bits (64 octets), le débit de 10Mb/s et la célérité du signal sur le câble
de 200Km/s (c’est sous évalué...) ?
Vous devez trouver 5,12Km, ce qui est trop. Dans la réalité il faut tenir
compte de l’affaiblissement en ligne qui ne permet pas de propager un signal
sur une telle distance sans pertes de puissance et distorsion en ligne. Ces
phénomènes obligent à placer des organes régénérateurs à des distances bien
plus courtes. On appelle ces organes de répéteurs car ils «répètent» les
bits, ils les régénèrent. Ce ne sont pas des amplificateurs car alors les
distorsions seraient elle-mêmes amplifiées.
Les premiers réseau Ethernet pouvaient compter des segments de 500m maximum, reliés par des répéteurs.
Les répéteurs apportent un retard, les câbles de raccordement de ces répéteurs au câble principal aussi. Le bilan des délais est tel que la taille maximale est de 2,5km pour les valeurs suivantes:

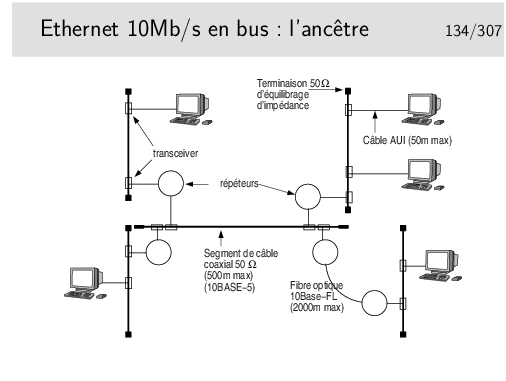
Le médium principal est constitué par des segments de câble 50Ω de 500m maximum, reliés entre eux par des répéteurs. Il ne peut y avoir plus de 5 segments entre deux stations (4 répéteurs). Les câbles sont terminés par un «bouchon» constitué par une résistance de 50Ω permettant d’équilibrer l’impédance caractéristique du support.
Un répéteur est un organe qui «répète» sur tous les ports les bits qui arrivent sur un port. Ce n’est pas une amplification car si cela était les altérations du signal seraient amplifiées. Les bits entrant dans un port sont reconnus et régénérés sur tous les autres ports et même sur les fils émission du port sur lesquels ils arrivent.
Les stations et les répéteurs sont raccordés au câble principal via des câbles de 50m maximum. Le câble arrive sur un organe de raccordement directement fixé sur le médium appelé le «transceiver».
Les transceivers doivent être placés à des distances multiples de 2,5m pour des contrer le phénomène des ondes stationnaires. Un point ou un anneau de couleur noire sur le câble (qui lui est jaune) indique les emplacements possibles.
Deux segments principaux peuvent être reliés par une fibre optique de longueur 2000m maximum. Les deux répéteurs aux extrémités de la fibre ne comptent alors que pour 1.
Ce type de réseau est aujourd’hui abandonné. Les segments de câble sont remplacés par des hubs (ou des switches) et l’architecture physique est devenue ainsi une étoile tout en continuant à fonctionner avec une technique de bus. Le hub peut être comparé à ne boite dans laquelle on aurait enfermé le câble et les transceivers.
Les dénominations 10BASE-5 et 10BASE-FL sont explicitées plus loin.
Il existe une version «cheaper net» comportant des câbles coaxiaux fins (de couleur noire), avec un raccordement par prises de type BNC. Ces câbles font 185m max (10BASE-2).
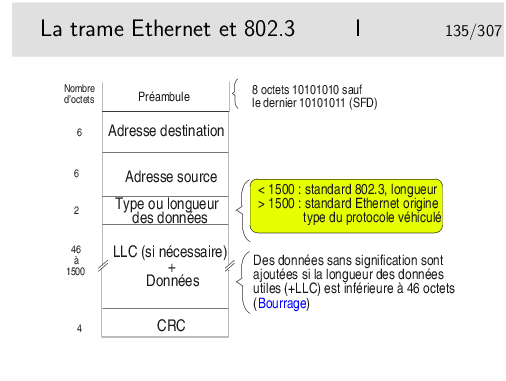
SFD: Start Frame Delimitor
Les créateurs d’Ethernet (Bob Metcalfe et Intel/Xeros/Digital)) ont défini
le champ «Type» pour porter l’identité du protocole véhiculé dans les
données (le champ type est le SAP). Pour des soucis d’interopérabilité avec
des réseaux locaux dont les trames n’ont pas ce champ type (Token Ring
802.5), le comité 802 a décidé qu’il serait obligatoire d’utiliser la couche
LLC pour porter l’identité du protocole véhiculé et a transformé le rôle de
ce champ en indicateur de longueur des données. Ce n’est pas une mauvaise
idée en soi.
Et en pratique ?...
En pratique les deux coexistent sur les mêmes supports. Une machine peut émettre en 802.3 pour certaines applications et en Ethernet pur pour d’autres.
Par défaut IP est véhiculé en Ethernet pur (type 0800hexa), il peut être véhiculé en mode 802.3 en paramétrant l’interface.


En terminologie anglo-saxonne les interfaces matérielles sont appelées NIC pour Network Interface Card.
Une interface voyant passer une trame de broadcast (diffusion) doit prendre en compte cette trame.
Une interface voyant passer une trame de multicast ne la prend en compte que si elle a été paramétrée pour cela.
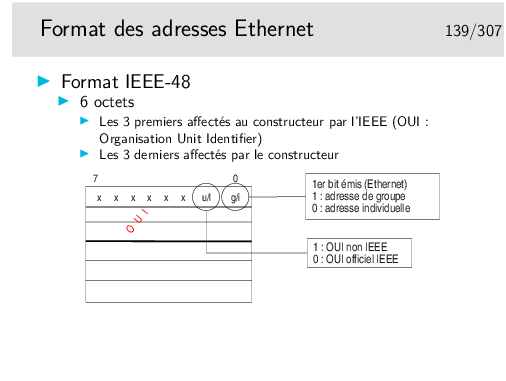

Information sur les OUI et adresses multicast:
http://standards.ieee.org/regauth/oui/oui.txt

http://standards.ieee.org/regauth/oui/oui.txt
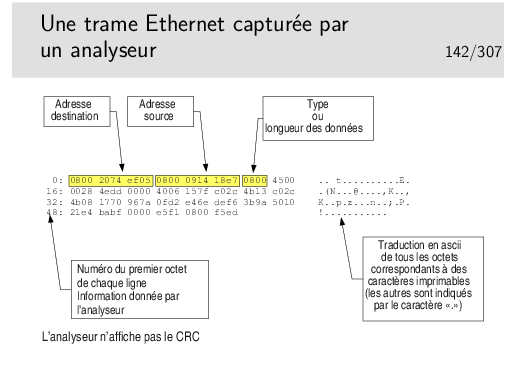
Cette trame est au format 802.3 ou Ethernet pur ?
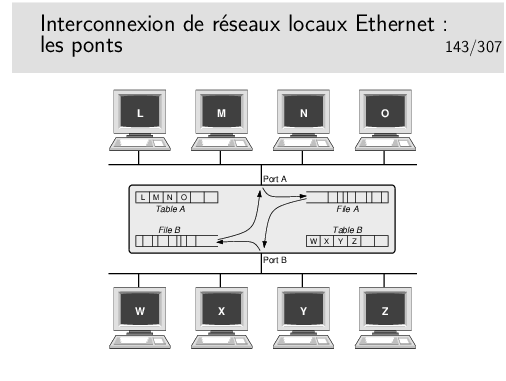
Le pont fonctionne tout seul sans paramétrage préalable. Il écoute le réseau sur son port A et son port B et «voit» passer des trames. Il enregistre les adresses sources de celles-ci et détermine ainsi que L, M, N et O sont du coté A. Ces adresses sont «apprises» par le pont et enregistrées dans sa table A. De même il «apprend» que, coté B, existent les stations W, X, Y et Z. Ces dernières adresses sont stockées dans la table B.
Si une trame est émise par L à destination de O, il reconnaît que ces deux stations sont du coté A, il ne fait rien. De même pour des trames de M vers N ou X vers Z par exemple.
Par contre si une trame est émise de A à destination de Z, alors cette trame est enregistrée dans la file A puis une tentative d’émission de celle-ci sera effectuée coté B. La trame ne sera mémorisée dans la file A que si elle n’a pas collisionné. Elle pourra peut-être collisionner coté B lors de sa ré-émission de ce coté mais la collision ne sera pas détectée coté A.
Si le pont ne connaît pas la station destinatrice (elle n’a rien émis encore) il retransmet les trames vers cette destination sur le port opposé de celui sur lequel il reçoit ces trames.
Avantages:
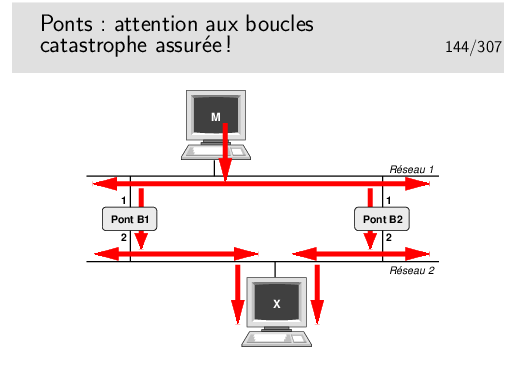
Pour des raisons de fiabilité on peut être amené à doubler les ponts entre deux réseaux. Se pose alors le problème de boucles comme l’exprime l’exemple présenté ici.
La machine M émet une trame à destination de la machine X.
Premier point négatif: multiplication des copies de trames...
Le pont B1 enregistre la trame et la réémet sur son port 2. La trame arrive à destination. Le pont B2 fait de même. Une seconde copie arrive à destination.
Second point négatif: les trames font des boucles...
Si la station X n’a rien émis encore les ponts ne la connaissent pas. La station M émet une trame vers X. Les ponts ne connaissant pas X retransmettent cette trame comme précédemment. Il y a donc deux copies. Mais...
La copie faite par B1 arrive à destination et aussi en B2 port 2. B2 croit alors que la machine M a changé de réseau, elle est maintenant en bas. Comme il ne connaît pas X il recopie cette trame sur son port 1. Cette trame sera vue par B1 port 1 qui va la relayer vers son port 2 et va à nouveau arriver en X puis en B2 port 2 et ainsi de suite. Mais une trame tournera aussi dans le sens contraire car au début la copie faite par B2 arrive à destination.. etc... etc... Une seule trame émise suffit alors à saturer le réseau.
Pour éviter ce phénomène il faut transformer le réseau. De graphe avec des boucles il faut le transformer en arbre complet, en anglais en «spanning tree».
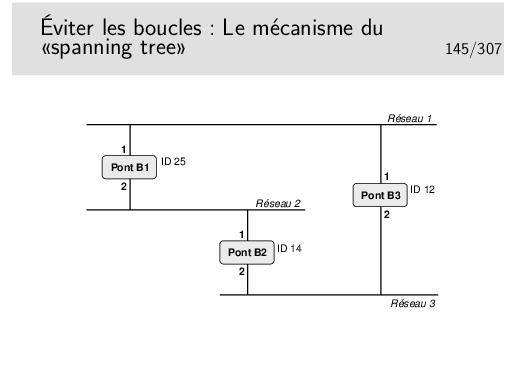
Les ponts (ou les commutateurs Ethernet) administrables peuvent mettre en œuvre cet algorithme. Sur chacun de ses ports, chaque pont annonce un identificateur qui lui est propre via une trame de type multicast (seuls les ponts sont configurés pour prendre en compte ce type de trame). Cet identificateur signifie en quelque sorte «c’est moi le pont racine». Tous les ponts commencent par annoncer qu’ils sont racine. Lorsqu’un pont reçoit un message comportant un identificateur «inférieur» au sien (on dira «meilleur»), il s’aperçoit qu’il n’est pas «racine» mais qu’un autre pont l’est plus certainement et que celui-ci est accessible via l’interface par laquelle est parvenue ce message «meilleur».
L’ensemble des ponts exécute le même algorithme, celui-ci converge finalement car un seul pont se trouve être le «meilleur», la racine (celui dont l’identificateur est le plus petit). Chaque pont sait par quelle interface atteindre le pont racine par le «plus court chemin», seule cette interface reste active pour le trafic de données, les autres interfaces permettant, elles aussi d’atteindre la racine, mais avec un chemin plus long sont inhibées pour le trafic de données. Les boucles sont ainsi évitées.
Les messages échangés s’appellent des BPDU (Bridge_PDU) et comportent les informations suivantes: <id_pont_supposé_racine, coût_supposé, id_pont_émetteur, port_émission>.
Les messages du protocole Spanning tree sont portés par des trames en
adressage multicast. Leur adresse destination est (en standard)
01:80:c2:00:00:00. Ce sont des trames de type 802.3. Les DSAP et SSAP
de la couche LLC supérieure (voir plus loin) sont égaux à 0x42. Les
messages sont émis toutes les 2 secondes par défaut. Les identificateurs,
les délais sont généralement paramétrables.
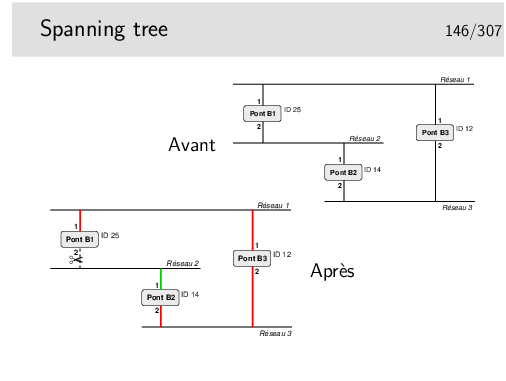
B1 émet: <25,0,25,1> sur son port 1 et <25,0,25,2> sur son
port 2.
Il reçoit <12,0,12,1> par son port 1 et <14,0,14,1> par son
port 2. Il constate qu’il n’est pas racine et que la racine doit être 12
(B2) accessible par son port 1. B1 considère que son port 1 est «root port».
Il émet alors: <12,1, 25,1> sur son port 1 et <12,1,25,2> sur
son port 2.
B2 émet <14,0,14,1> sur son port 1 et <14,0,14,2> sur son port
2.
Il reçoit: <12,0,12,2> port 2 et <25,0,25,2> port 2 dans une
première phase indiquant ainsi que le pont racine doit être accessible par
son port 2 plutôt que par son port 1. B2 considère que son port 2 est «root
port».
Il émet alors: <12,1,14,2> sur son port 2 et <12,1,14,1> sur
son port 1.
B3 ne reçoit pas de «meilleure» configuration que celles qu’il émet. Il est donc la racine.
Comment vont alors se départager B1 (port 2) et B2 (port 1) ?
B1 reçoit port 2: <12,1,14,1> ce qui est meilleur que ce qu’il émet
sur ce même port <12,1,25,2>. Il inhibe son port 2 (pour le trafic de
données, pas pour les messages de spanning tree). B2 reçoit sur son port 1
un message «moins bon» que ce qu’il émet sur ce même port, donc B2 port 1
reste actif.
Excellent tutorial animé à:
http://www.cisco.com/warp/public/473/spanning_tree1.swf
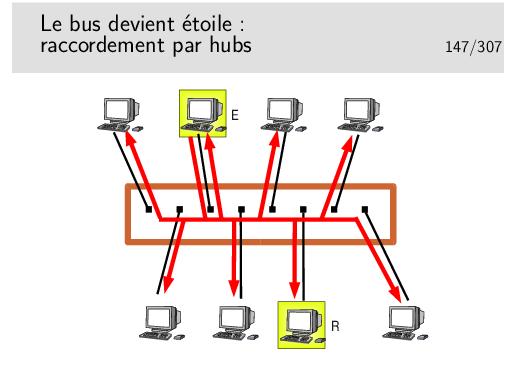
On prend le câble et les transceivers, on ramasse le tout dans un petit boîtier et le tour est joué. D’une topologie en bus nous passons à une topologie en étoile.
En fait ce n’est pas si simple car les raccordement changent, ce ne sont plus des transceivers mais des prises de type RJ45 et les câbles sont de type 10/100 BASE-T, à paire torsadée, de longueur max 100m.
Exemple de fonctionnement: La station E émet vers la station R. Toutes les stations reçoivent le signal, même E pour des raisons de détection de collision.
Un hub se comporte donc comme un bus.
Il est très facile d’espionner tout ce qui passe sur le hub à partir d’une machine raccordée sur un des ports.
Les hubs sont des répéteurs. Ce sont des organes de la couche physique (selon le modèle OSI), ils ne s’intéressent qu’au niveau bit.
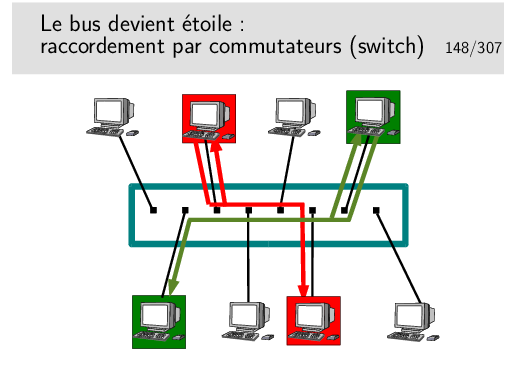
Le commutateur ressemble à un hub mais se comporte comme un pont. Il connaît les adresses (MAC) des machines qui sont raccordées sur chacun de ses ports (raccordées directement ou via d’autres d’autres commutateurs ou hubs). C’est un pont multiport.
Il ne recopie une trame que sur le port qui mène vers la destination.
Il peut faire ce travail pour plusieurs trames simultanément à condition qu’elles n’aillent pas vers le même port de sortie, auquel cas elles sont traitées les unes après les autres. Il se comporte donc comme s’il était capable d’établir des circuits entre deux ports pour de cours instants, d’on son nom de commutateur (switch en anglais).
C’est une commutation de niveau 2 (plus exactement de niveau MAC), à ne pas confondre avec la commutation de niveau 3 qu’on rencontre dans d’autres réseaux comme X25 ou ATM.
L’espionnage sur ce type d’appareil est plus difficile, sur un port donné on ne peut voir que les trames destinées à ce port ou les trames de broadcast, l’intérêt pour «l’espion» est donc très limité. Le «malfaisant» persévérant et cultivé en Réseaux peut cependant trouver des solutions...
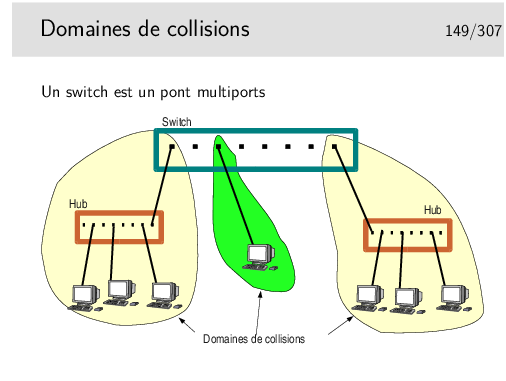
Un switch se comporte comme un pont. Sur chacun de ses ports il enregistre les adresses sources des trames qu’il voit passer. Chaque port se comporte comme un port de pont. Chaque port délimite donc un domaine de collision.
On voit sur la figure ci-dessus qu’un de ces domaines ne comporte que deux machines (un port du switch et une machine seule), Voir le transparent suivant pour une utilisation plus efficace du lien en question.
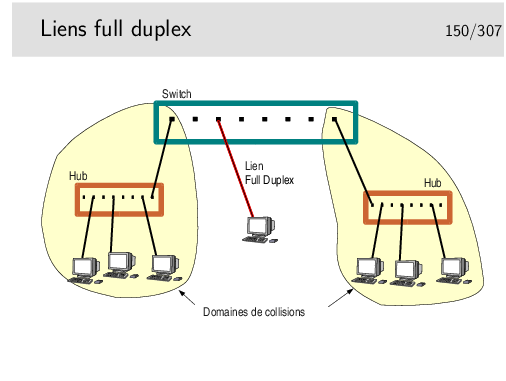
Lorsqu’une machine terminale est reliée directement à un switch le domaine de collision est restreint à la machine et au port du switch sur lequel elle est raccordée. Si on considère en plus que le lien physique de raccordement est un câble comportant un circuit différent pour chaque sens (deux fils par pour l’émission, deux autres fils pour la réception, ou deux fibres optiques), il devient alors intéressant d’inhiber le mécanisme de détection et contention de collision pour tirer partie pleinement de la paire émission et de la paire réception présente dans le câble de raccordement en les utilisant simultanément pour véhiculer des données utiles.
On peut ainsi passer de 10/100/1000 Mb/s à l’alternat à 10/100/1000 Mb/s dans chaque sens simultanément (10 ou 100 ou 1000 MB/s selon le matériel).
Attention, en général il faut gérer le full duplex, c’est à dire qu’il faut se connecter au switch pour l’administrer (sur son port console via un PC et l’application HyperTerminal ou via telnet en IP) et configurer les ports qu’on désire voir fonctionner dans ce mode. Il faut aussi vérifier sur la machine terminale qu’elle est bien en full duplex et, éventuellement, la forcer dans ce mode. Si le full duplex n’est pas positionné des deux cotés il en résultera un fonctionnement très ralenti, une des deux extrémités détectant alors des collisions qui n’en sont pas.


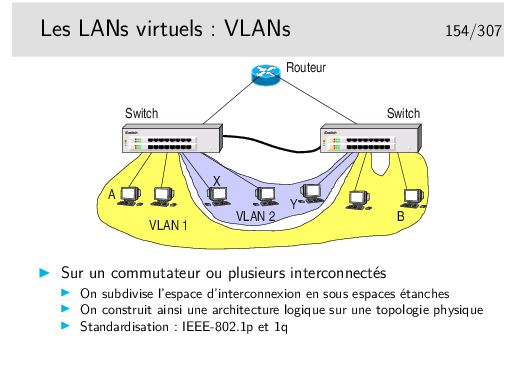
Imaginons que la machine A veuille émettre vers toutes les machines de son VLAN, elle doit émettre une trame de broadcast qui devra être relayée par le switch de gauche vers le switch de droite. Cependant, le switch de droite devra connaître l’identité du VLAN vers lequel diffuser la trame. Il ne faudra pas, par exemple, émettre vers la machine Y du VLAN2. Pour cela, sur le lien entre les switches, la trame devra être complémentée par un champ porteur de l’ identité du VLAN.
Le transparent suivant indique comment est modifiée la trame ethernet de base.
Le lien d’interconnexion des commutateurs est parfois un «trunk». Selon les constructeurs et les types de switches, des ports spécifiques peuvent être réservés pour le «trunking».
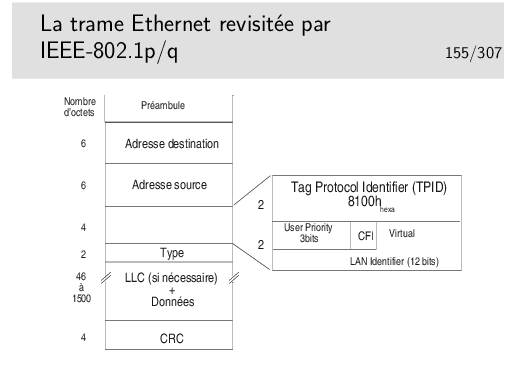
Le champ TPID est tout simplement une valeur de champ Type spécifique. Le champ «User Priority» apporte une possibilité de privilégier certains flux.
Le bit CFI (Canonical Format Indicator), s’il est à 1, indique que le champ information comporte des indications de routage par la source.
Le champ «Virtual LAN Identifier» indique à quel VLAN appartient la trame.


Sonet (Synchronous Optical Network) est un type de multiplexage mis au point par la société américaine Bellcore et standardisée par l’ITU-T sous l’appellation SDH (Synchronous Digital Hierarchy).
À l’origine, Sonet/SDH est destiné au transport des voies téléphoniques numériques. Les concepts mis en œuvre permettent un multiplexage et un démultiplexage facilité par rapport aux techniques plus anciennes. C’est le support privilégié pour les réseaux de type ATM.
Les débits courants sont de 155Mb/s (Sonet: 0C3, SDH: STM1) sur cuivre (100m) ou fibre optique et 622Mb/s. Le débit de 1,2 Gb/s est possible. Un bond technologique est réalisé pour l’Ethernet 10Gb/s.

Un lien: http://cablingdb.com/GlossaryPages/GlossaryC/CGlossary.asp

Les matériels à 10Mb/s tendent à disparaître aujourd’hui (2004). Les cartes interfaces sont toutes en 100-BASE-T, même en premier prix.

Un document bien illustré sur le câblage... En italien, mais Mhz et nm et Km s’écrivent comme en français... http://www.garr.it/ws4/pdf/Montessoro.pdf
Un câble croisé permettra de raccorder:
Les hubs et les switches peuvent être munis de ports directement croisés, on les repère généralement par la mention «Up Link». Un port peut aussi avoir deux prises RJ45, und roite et une croisée «up-link».
Un port peut être muni d’un petit commutateur appelé MDI-MDIX permettant de positionner le port en mode normal (MDI) ou en mode croisé (MDIX).
Et enfin, la fonction MDI-MDIX peut être à auto-détection: le switch détecte automatiquement s’il a à faire à un câble droit ou croisé.




Technologie des débuts 90.
Aujourd’hui on ne trouve plus que du 10/100/1000 BASE-T, à quelques Euros...
Et en plus il y a beaucoup moins de composants...


L’envers du décor:


La fonction «monitoring» consiste à rediriger le trafic normal d’un port vers un port dédié à la fonction et sur lequel on place une machine munie d’un analyseur de flux. Toutes les trames entrantes et sortantes du port surveillé sont recopiées sur le port de monitoring.

Un tutorial correct:
http://www.intelligraphics.com/articles/80211.article.html
Un lien sur la sécurité en 802.11:
http://www.iss.net/wireless/WLAN.FAQ.php
Autre lien intéressant:
http://wireless.ictp.trieste.it/school.2002/lectures/ermanno/HTML/802.11_Architecture.pdf#search='802%2011%20ssid'

Un lien intéressant http://vlan.org/breve123.html
Les canaux synchrones de IEEE-1394 (FireWire/iLink) sont adaptés à la transmission de flux sons et images.
Ces réseaux utilisent des protocoles spécifiques pour les couches supérieures, par exemple AMDTP (Audio and Music Data Transmission Protocol. IEC61883-6) pour IEEE-1394. IP n’est pas implémenté en standard sur ces réseaux.
Une émulation Ethernet existe pour IEEE-1394 en utilisant les canaux asynchrone.
FireWire: IEEE-1394 chez Apple.
ilink chez Intel


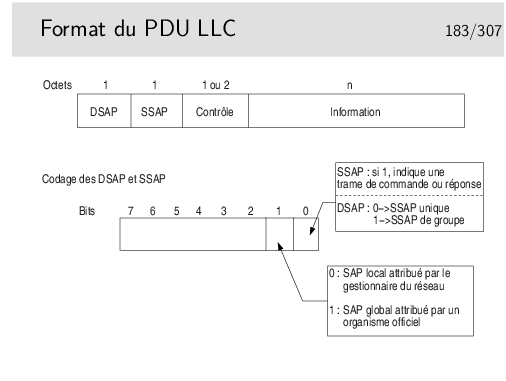
Et donc ... il reste combien de SAP possibles, donc de protocoles identifiables ?
64 ! C’est bien peu et c’est un problème...
La notation 0x... est celle du langage C ou Java pour les nombres en hexadécimal.
Le SAP 0x7E ne vous rappelle rien concernant X25 et surtout sa couche 2 standard ?


SNAP: même traduit un français, ça ne veut rien dire (humour (?!!!))
OUI: Organizational Unit Identifier

Mais non !... Ce n’est pas si compliqué !...
Et en plus tout peut être justifié... Il y a une bonne raison pour qu’il en soit ainsi. Simplement il faut chercher cette raison parfois profondément...
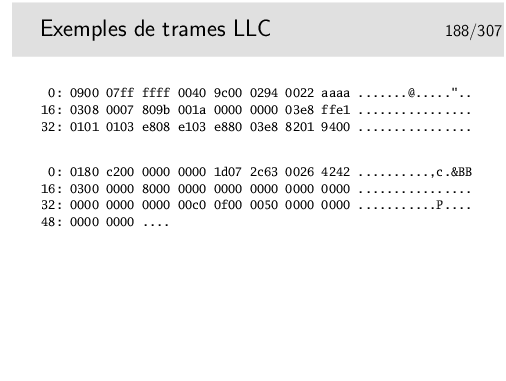
Décodons... Et répondons aux questions:
Partie III |

Il existe aussi l’ICANN (The Internet Corporation for Assigned Names and Numbers) société de droit privé destinée à remplacer IANA. L’ICANN a été fondée en 1998 et on a parfois du mal à faire la distinction entre ses responsabilité et celles de IANA qui continue d’exister.
Voir un article de synthèse sur ce lien: http://www.renater.fr/Projets/ICANN/


Les RFC sont en ASCII 7bits pur... Quelques activistes à l’IETF osent militer pour y introduire un peu de HTML (au moins pour le renvoie vers les sections ou la table des matières): http://www.catb.org/~esr/rfcs-in-html/index.html
Les RFCs sont classés dans leur ordre de parution, il n’y a pas de classement thématique (hors les std).
Parmi les RFCs du premier avril citons par exemple celui spécifiant le protocole permettant d’envoyer des messages subliminaux (rfc1097), celui spécifiant comment utiliser IP sur une couche liaison de type «pigeons voyageurs» ou plus exactement des «avian carriers» (rfc1149) le MTU des messages étant proportionnel à la longueur de la patte de l’oiseau...
Mais tous les RFC «premier avril» ne sont pas des plaisanteries... Le 777 est par exemple celui qui spécifie ICMP (Internet Message Control Protocol), et ce protocole est loin d’être humoristique...

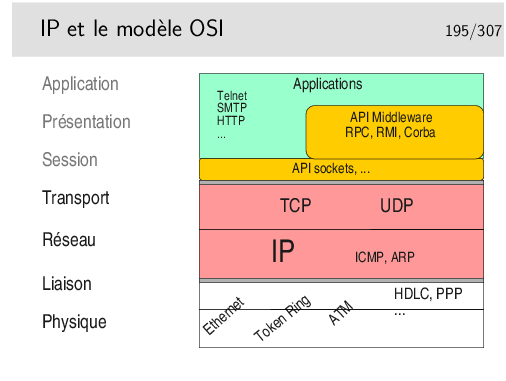
Clairement, IP est au niveau 3 et TCP/UDP au niveau 4.
Quand bien même ces protocoles ne sont pas conformes à ceux qui ont été spécifiés pour le modèle OSI, on peut leur trouver ces places dans le modèle.
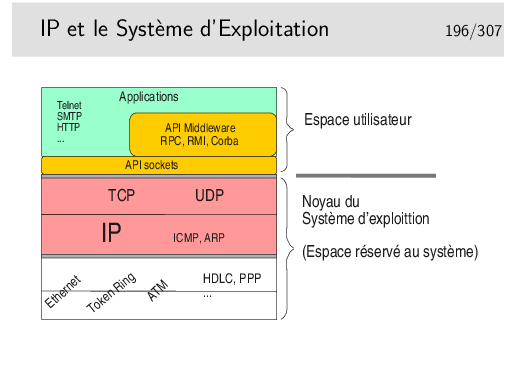
Les couches protocolaires jusqu’au niveau 4 sont inclues dans le noyau. Les applications (les programmes des utilisateurs) y accèdent via des interfaces qui les masquent.
Ces interfaces sont constituées par des bibliothèques de fonctions formant des APIs utilisables par les programmeurs d’applications. La plus répandue est la bibliothèque socket tout à fait bien adaptée aux protocoles Internet (TCP, UDP, IP). Les couches protocolaires sont vues comme des fichiers qu’on écrit ou qu’on lit. Le transfert de données est aisé puisqu’il se fait comme avec des fichiers. Le portage est aisé vers le monde Windows qui implémente aussi cette interface programmatique issue des Unix de Berkeley (les sockets BSD).
Un autre type d’API est lui aussi très répandu puisqu’il est utilisé pour NFS et NIS. Au départ spécifié par SUN dans les années 80 il est depuis universel sous Unix. Il s’agit des Remote Procedure Calls ou RPC. La couche RPC offre une abstraction du réseau et permet d’appeler des fonctions en local alors qu’elles s’exécutent à distance.
Le concept a été poussé encore plus loin et adapté aux langages orientés objet comme C++ avec CORBA (Common Object Broker Architecture) qui permet d’appeler des méthodes sur des objets situés sur des machines distantes. Cette interface n’est cependant pas standard (du point de vue API) et plusieurs implémentations existent, la plupart commerciales et d’autre libres comme ORBit qui est utilisé par GNOME sous Linux.

Longueur d’entête: en nombre de mots de 32 bits ; si supérieur à 5, indique la présence d’options (40 octets max d’options: 10 mots max de 4 octets)
Type de service: peu utilisé par le passé, permet aujourd’hui, entre autres, de coder le DSCP (DiffServ Code Point). Voir pages suivantes.
Champs pour la segmentation: on recommande d’éviter la segmentation avec TCP. Elle n’existe plus que pour UDP si les unités de données fournies ont une taille supérieure au MTU de l’interface
bit D: Don’t fragment: interdit la fragmentation du segment s’il est à 1
bit M: More: indique la présence de fragments complémentaires, si le segment d’origine a été fragmenté.
Si le champ Offset est à 0 ainsi que le bit M, le segment est celui d’origine
TTL: durée de vie; décrémenté de 1 par chaque routeur. Si le résulat passe à 0, le datagramme est jeté et un message ICMP est envoyé à la machine émettrice
Protocole: indique le protocole supérieur véhiculé (TCP, UDP, ICMP voire même IP en cas d’encapsulation IP dans IP piour tunnelling)
Somme de contrôle d’entête: contient la somme des mots de 16 bits constituant l’entête. Permet à l’arrivée de vérifier l’intégrité de celle-ci. Si une erreur est détectée le datagramme est jeté sans autre forme d’action. On ne peut même pas envoyer un message d’erreur à l’émetteur car l’adresse source qui indique ce dernier peut être corrompue. Comme l’indique le nom de ce champ le contrôle d’intégrité n’est fait que sur l’entête.
Adresses: source et destination, sur 32 bits ; information fondamentale, au moins en ce qui concerne la destination car elle sert au routage.

RFC 791 et 795

DiffServ signifie Différentiation de Service (en anglais aussi). C’est un mécanisme relativement récent permettant de marquer les paquets afin qu’ils soient traités de manière différentiée dans les routeurs. C’est un mécanisme de qualité de service.
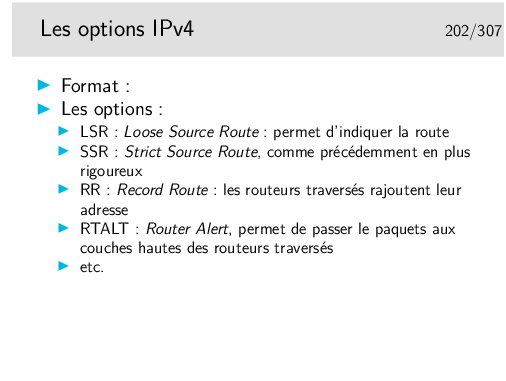
L’option LSR permet d’indiquer la route à suivre mais si un routeur intermédiaire ne sait pas comment utiliser une des indications contenue dans l’option, il peut alors utiliser sa table de routage normale.
L’option SSR est plus stricte car le paquet est rejeté si un routeur ne sait pas l’orienter vers une direction indiquée.
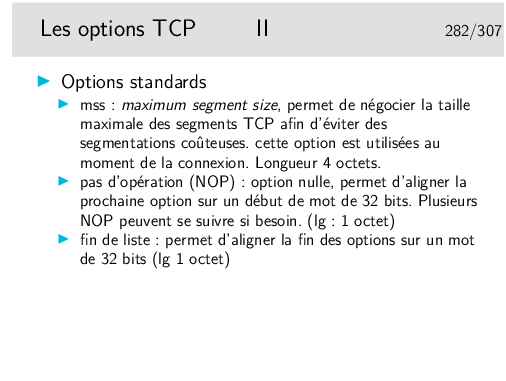
Il y a encore l’option Traceroute, obsolète car dangereuse, EEOL et NOP pour indiquer la fin de la liste et du bourrage d’alignement sur 32 bits.
L’option RTALT est utilisée par IGMP et par RSVP, ces protocoles nécessitent des traitements particuliers dans les routeurs. Ces traitements sont effectués par des entités applicatives des routeurs. Ces derniers ne doivent donc pas effectuer le routage rapide des paquets munis de cette options mais ils doivent les diriger vers les entités applicatives.
http://www.iana.org/assignments/ip-parameters
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| Traffic Class | Flow Label |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload Length | Next Header | Hop Limit |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Source Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Destination Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload... |
+---------------+------------------------
| IPv6 header | TCP header + data
| |
| Next Header = |
| TCP |
+---------------+------------------------
+---------------+----------------+------------------------
| IPv6 header | Routing header | TCP header + data
| | |
| Next Header = | Next Header = |
| Routing | TCP |
+---------------+----------------+------------------------
+---------------+----------------+-----------------+-----------------
| IPv6 header | Routing header | Fragment header | fragment of TCP
| | | | header + data
| Next Header = | Next Header = | Next Header = |
| Routing | Fragment | TCP |
+---------------+----------------+-----------------+-----------------

Une interface IP doit être munie d’une adresse pour pouvoir fonctionner. En général, pour des machines de bureau standard en réseau local, l’interface IP correspond à une carte réseau de type Ethernet.
L’interface IP peut aussi être correspondre à une couche complètement logicielle, c’est le cas des interfaces de niveau 2 réalisées avec le protocole PPP qui s’interpose entre IP et une interface physique comme un port série ou un port USB relié à un modem ADSL (l’empilement des couches protocolaires est alors très complexe).
Une interface matérielle peut être munie de plusieurs adresses IP, sous Unix et Linux en particulier. On a alors, par exemple, les interfaces eth0:0, eth0:1, eth0:2, etc.
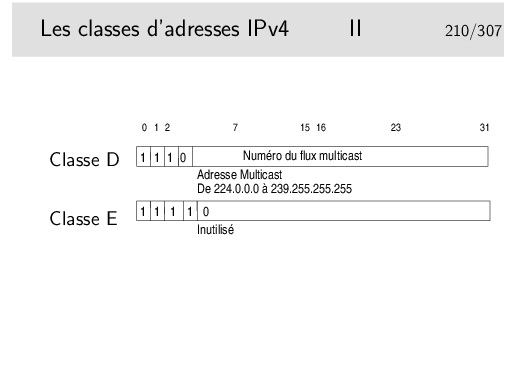
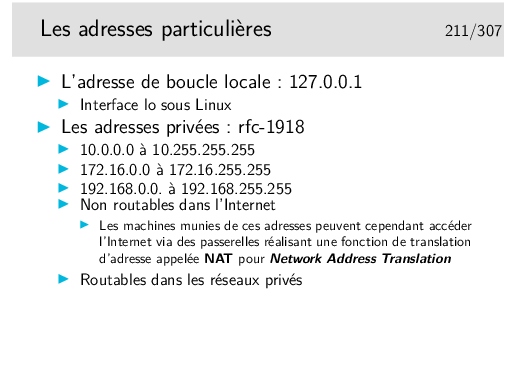
A noter que les adresses de classe A de la gamme 0.0.0.0 à 0.255.255.255 ne peuvent pas être utilisées, bien qu’elles ne correspondent pas à une fonction particulière.

Le multicast...
Permet d’envoyer des paquets IP à un certain nombre de machines mais pas à toutes. Des machines sur le réseau peuvent être sources de trafic multicast, elles peuvent émette par exemple à l’adresse 224.5.6.7. Il suffit que d’autres machines soient «au courant» de ce fait pour se mettre en écoute en lançant une application spécifique. Cette application demande explicitement à écouter le flux en envoyant un message du protocole IGMP (RFC-3376 pour la version 3) vers l’Internet. Ce message est relayé par les routeurs vers les sources, chaque routeur rencontré s’insère alors dans un arbre de diffusion multicast (préalablement configuré). Les paquets du flux applicatif peuvent arriver ainsi aux récepteurs ayant fait la requête.
Il faut que les routeurs soient configurés, ce n’est pas automatique.
Il existe un réseau mondial multicast, appelé le MBONE. Les sources potentielles diffusent des annonces de session à l’adresse SAP.MCAST.NET (224.2.127.254) (en UDP, port 9875).
L’outil sdr (pour unix/linux ou windows) permet d’écouter ce flux et afficher les informations de sessions.
(mot clé MBONE; un lien: http://www-itg.lbl.gov/mbone/)

La fonction de NAT est mise en œuvre dans un routeur muni d’une interface configurée avec une adresse officielle (pouvant donc être routée dans l’Internet). Les paquets sortant sont modifiés, le champ «adresse source» est remplacé par l’adresse officielle de l’interface de sortie du routeur. Ce dernier mémorise l’opération pour effectuer la modification inverse pour les paquets en retour.
Des extensions du concept peuvent affecter aussi les ports TCP ou UDP.
Le mécanisme pose un problème pour les protocoles tels que ftp. En effet, ftp demande la création d’une connexion «entrante» pour réaliser les transferts de fichiers, les paquets de demande de connexion doivent être corrélés avec la connexion sortante existante. Les traitements sont alors plus complexes que pour les connexions simples comme celle pour le Web par exemple). Ces concepts demandent de comprendre ce qu’est une connexion au niveau supérieur (il n’y a pas de connexion IP). Ce point sera abordé plus loin dans le chapitre sur TCP.
Sous linux, les mécanismes de translation d’adresse sont directement intégrés au noyau. Une commande permet d’en paramétrer les caractéristiques, il s’agit de iptables qui peut bien plus encore en ce qui concerne les opérations de filtrage pour la sécurité.

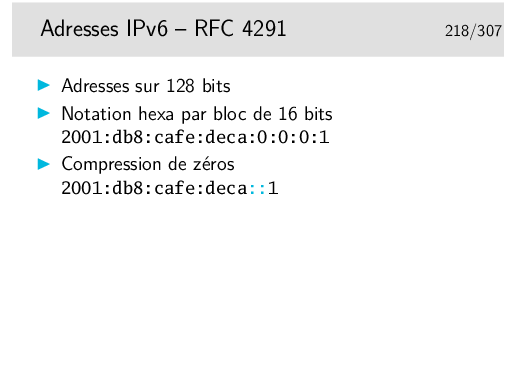
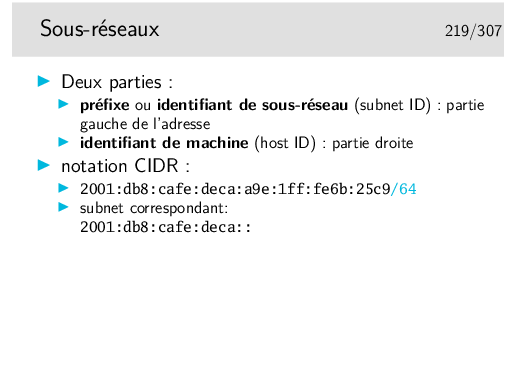
Pardon pour l’Académie, mais «subnetting» est plus joli que «sous-réseautage»
Avec le masque 255.255.255.224 on prend 3 bits de la partie machine. On pourra créer 8 sous réseaux à partir du numéro 192.168.100.0:
Question: à quel sous réseau appartient la machine de numéro 192.168.100.72 ?

Dans le dernier exemple, l’adresse donnée est une adresse de réseau et non une adresse de machine. Avec une telle adresse (et son masque) on pourra adresser deux fois 128-2 machines: de 192.168.100.1 à 192.168.100.126 (broadcast 192.168.100.127) et de 192.168.100.129 à 192.168.100.254 (broadcast 192.168.100.255).
La notation classique (255.255...) reste très répandue. La notation CIDR peut se rencontrer sous quelques Unix (BSD, Linux, ???), elles est plus commode d’utilisation.

Le protocole PPP est utilisé par exemple dans les connexions aux fournisseurs de service IP via des modems et le réseaux téléphonique général.
Dans les connexions via ADSL, c’est aussi PPP qui est utilisé pour affecter l’adresse à la machine qui se connecte mais le mécanisme est beaucoup plus complexe.
Le protocole DHCP permet de fournir une adresse IP, le netmask associé, le routeur par défaut pour l’interface en cours de configuration, le nom de domaine DNS ainsi que le ou les serveurs DNS. Tout ceci pour une période de temps configurée par le gestionnaire du serveur DNS. Les clients doivent renouveler leur demande d’adresse à la fin du temps alloué.





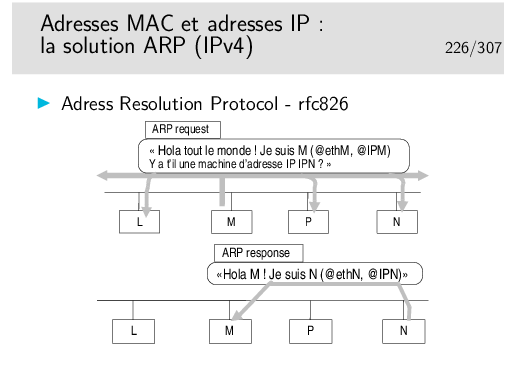
Comment la machine M peut elle retrouver l’adresse Ethernet de la machine N en ne connaissant que l’adresse IP de N ?

Soyez curieux: la commande arp
Sur un réseau local, sous Windows ou Unix/Linux, ouvrez une fenêtre de commande et tapez: arp -a pour voir la table de résolution arp instantanée. Si vous ne voyez pas la machine de votre voisin et que vous connaissez son adresse IP (ou son nom), faites un «ping» dessus: ping 192.168.100.5 par exemple.
Si la réponse du ping est positive, refaites alors immédiatement arp -a, vous verrez apparaître la résolution concernant la machine voisine.

Soyez curieux: la commande ip neigh
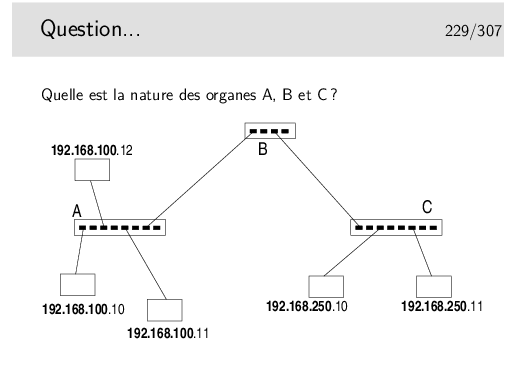
Vous avez le choix entre trois types d’organes:
Aide technique: le netmask est standard pour la classe d’adresses IP utilisée...
Et cette classe est la classe ?????....
???
???
...C !
Ce sont des adresses de classe C...
Or les parties «Réseau» ne sont pas identiques entre la partie droite du schéma et la partie gauche...
Donc... Il ne s’agit pas de mêmes «Réseaux». Donc, forcément B est un... et A et C sont des ... ou des ...

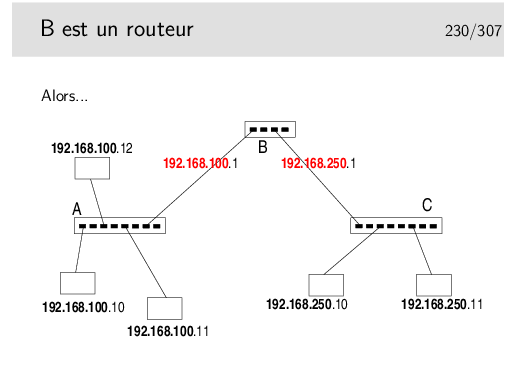
Réponse à la question... A et B sont des hubs ou des commutateurs (ou switches ou ponts multiports). Même si fondamentalement les fonctionnalités des hubs et des commutateurs sont différentes (hubs: répéteurs, organes physiques, niveau 1 ISO – switches: niveau 2 ISO) on ne peut pas faire la différence sur le schéma.
B est un routeur. Il raccorde des réseaux dont les machines sont identifiées par des numéros IP de classe C dont la partie réseau est différente. Il raccorde dont des réseaux. Il fonctionne au niveau 3 ISO.
B est un routeur, donc chacun de ses ports est identifié par une adresse IP dont la partie réseau identifie le réseau auquel ce port est raccordé.
Le premier port de B est raccordé sur le réseau 192.168.100.0, on lui donnera donc une adresse libre de ce réseau (ici .1). Un autre port est sur le réseau 192.168.250.0, on lui donnera par exemple l’adresse .1 sur ce réseau.
Ce n’est pas pour faire joli, c’est vraiment fonctionnel. Si on ne le fait pas le réseau ne peut pas fonctionner.
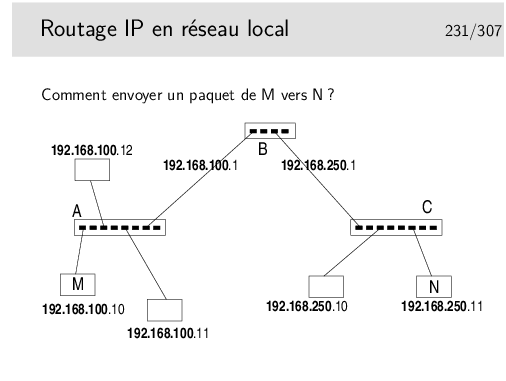
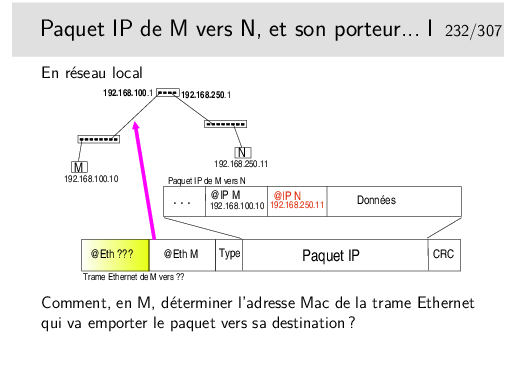
Rien n’est magique... L’application sur M qui désire envoyer un message à une application sur N doit savoir que N existe. Sur M on doit connaître l’adresse IP de N.
On doit aussi savoir par où on passe. En M on doit savoir que pour atteindre N il faut passer par le routeur B.
Mais B est identifié par deux adresses IP!!!
En M, nous sommes sur un réseau local, nous ne pouvons atteindre que des machines se trouvant sur le même réseau local que nous. Nous ne pouvons donc atteindre le routeur que par son port qui est situé sur le même réseau physique, celui identifié par le préfixe IP 192.168.100.
...Comment faire ?...
À suivre...
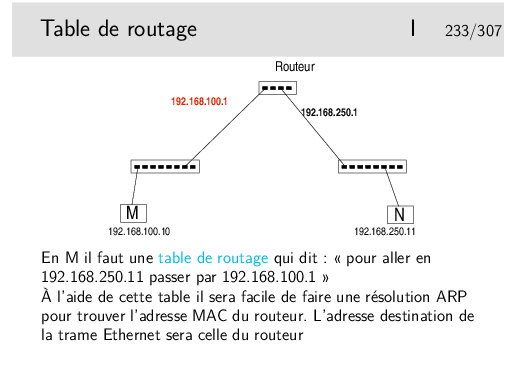
Il faut une table de routage en M. Donc dans la machine terminale!!!
Chaque machine, quelle soit terminale ou intermédiaire, travaillant en IP incorpore des fonctions de routage.
Cela ne signifie pas que chaque machine terminale soit un routeur... Pour qu’une machine puisse joue le rôle de routeur il faut qu’elle possède au moins deux interfaces munies d’adresses IP (autres que 127.0.0.1, correspondant à l’interface boucle locale) et que son module IP soit autorisé à effectuer la fonction de relayage (forwarding).
Quand on disait qu’affecter une adresse à chaque interface de routeur n’était pas un effet de cosmétique...
Si en M on ne connaît pas l’adresse IP de l’interface du routeur qui est du même coté que M (sur le même réseau) alors la résolution ARP ne peut se faire.
Il ne suffit pas que l’interface du routeur et M soient «du même coté», il faut aussi qu’ils soient sur le même réseau local pour que ARP fonctionne (on rappelle que la requête ARP est transmise par broadcast Ethernet et que ce type de message ne passe pas les routeurs).
Ici la notion de réseau local est celle qui a été vue dans la partie précédente du cours, à savoir un réseau où la diffusion est possible vers toutes les machines. Ce pourrait être un VLAN car ce type de topologie définit des domaines de broadcast.
Lorsque des machines sont reliées entre-elles via des liaison point-à-point, il n’y a pas de résolution ARP.
Les directions sont spécifiées par des numéros de réseaux indiqués sur 4 octets et accompagnés de leur netmask, par exemple 192.168.10.0 255.255.255.0, ou en notation CIDR 192.168.10.0/24. Attention, la notation CIDR peut ne pas être comprise par tous les routeurs. Elle l’est pour les machines Unix Linux ou BSD.
Une direction peut être une machine, dans ce cas l’adresse IP de la machine est indiqué directement et le netmask vaut 255.255.255.255.
Les indications de route peuvent être données en indiquant l’adresse IP du routeur par lequel il faut envoyer les paquets pour la direction correspondante. Plus précisément il s’agit de l’adresse IP de l’interface du routeur immédiatement accessible. C’est absolument obligatoire dans le cas ou l’interface du routeur en question est sur un réseau local classique.
Dans le cas ou l’interface du routeur est sur une liaison point-à-point, on peut ne donner que le nom de l’interface locale. Voir transparent suivant.
Le coût correspond à la notion de «plus court chemin». Moins le coût est grand meilleur semble le chemin (ce n’est pas toujours vrai, un chemin peut être plus court en vraie distance (moins de sauts par exemple) et cependant moins efficace en débit).
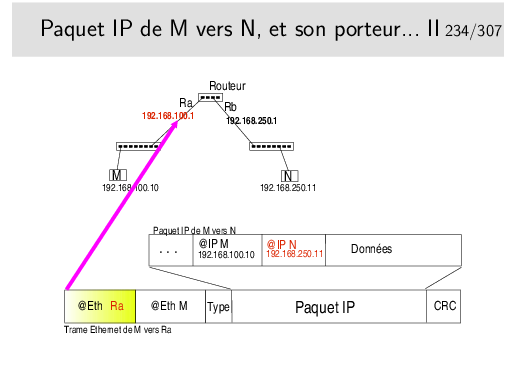
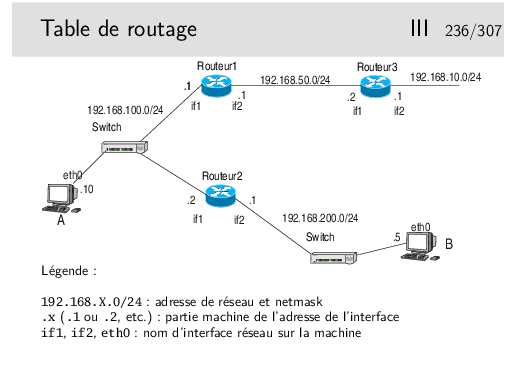
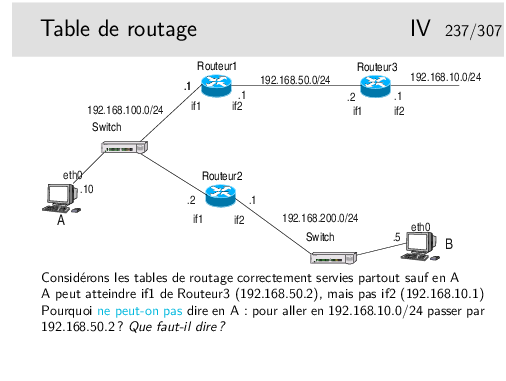
Table de routage en A
| direction | netmask | gateway | interface |
| 192.168.100.0 | 255.255.255.0 | 192.168.100.10 | eth0 |
| 192.168.200.0 | 255.255.255.0 | 192.168.100.2 | eth0 |
| default | 0.0.0.0 | 192.168.100.1 | eth0 |
Rq: ici la mention de l’interface n’est pas très importante, elle est redondante car il n’y a qu’une seule interface physique (il y a quand même l’interface boucle locale qu’on n’a pas fait figurer dans la table de routage, mais qui exite et provoque des entrées spécifiques dans la table)
Table de routage en Routeur1
| direction | netmask | gateway | interface |
| 192.168.50.0 | 255.255.255.0 | 192.168.50.1 | if2 |
| 192.168.100.0 | 255.255.255.0 | 192.168.100.1 | if1 |
| 192.168.200.0 | 255.255.255.0 | 192.168.100.2 | if1 |
| default | 0.0.0.0 | 192.168.50.2 | if2 |
Rq: dans la ligne par défaut, la seule mention de l’interface suffirait car le lien entre les routeurs 1 et 2 est de type point-à-point.
Compléter pour le routeur 2 et la machine B...

On suppose la table de routage en A partiellement remplie. L’interface if1 du routeur2 est accessible, une commande ping, depuis A, vers l’adresse de cette interface fonctionne. Donc on peut supposer (et on a raison) que cette interface est «visible» depuis A. Cependant si on tente de créer en A une route via cette interface la commande doit échouer. Pourquoi ?
Quelle est le numéro de l’interface de boucle locale (interface interne non raccordée à un réseau physique)?
Quelle sont les adresses de broadcast possibles ?
Par quelle interface sont acheminés les paquets de broadcast ?
Que pouvez vous déduire de tout ceci concernant l’adresse de la machine en question ?
Que se passe-t’il si une application de cette machine envoie un paquet IP vers une autre application de la même machine ? Quel chemin est emprunté par le paquet ?
Quelle adresse code la destination par défaut ?
Et n’oubliez pas la commande ping... C’est la première commande à utiliser quand le réseau ne va pas très bien... «Mon voisin est-il joignable ? Alors:
ping mon_voisin (plutôt adresse_IP_de_mon_voisin)
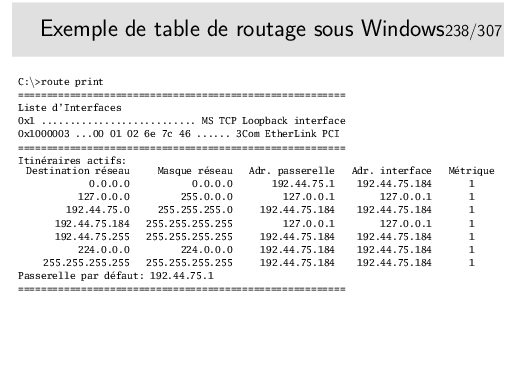
Note: Vous remarquerez peut être que Windows affiche plus de routes que Linux. En fait Linux gère plusieurs tables de routage et a pour habitude de n’afficher que la table main, sauf si on lui demande gentiment. (Pour avoir la liste des tables de routage: cat /etc/iproute2/rt_tables; pour afficher la table principale: ip route show table main; pour afficher la table avec les règles pour le multicast et le broadcast: ip route show table local; etc.)
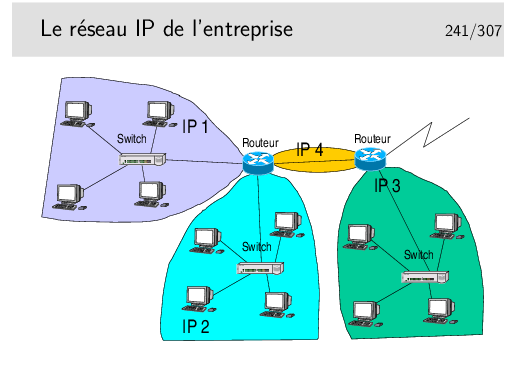
Ce que l’on va appeler le «réseau local» de l’entreprise est en réalité un réseau de niveau 3 composé de routeurs interconnectant des réseaux locaux séparés physiquement ou logiquement (VLANs).
L’adressage pourra être de type «privé», avec une seule adresse officielle en sortie et une fonction de type NAT dans le routeur de sortie.


Un AS (Autonomous System) est un grand système réseau (typiquement un fournisseur d’accès) qui gère de manière cohérente et autonome son routage. Les numéro d’AS (utilisé notemment dans le routage BGP, cf. plus loin) sont attribués par les RIR (Regional Internet Registry) sous l’autorité de l’IANA. Le RIP européen est RIPE-NCC (Réseaux IP Européens - Network Coordination Centre).
Par exemple en 2015 on dénombre 1208 "opérateurs" qui offrent des services sur le territoire français: http://www.ripe.net/membership/indices/FR.html. (Ne pas croire que les seuls opérateurs sont Orange SFR Bouygues...)
Ces grands systèmes ont un numéro d’AS: France Télécom (AS3215), Proxad (AS12322), LDCOM Networks (AS15557 gaoland.net), Cegetel (AS8228), 9TELECOM(AS12626 9tel.net), AOL France customers , SIRIS (AS3305 siris.fr), KAPTECH(AS6760 kaptech.net), BELGACOM France (AS6771), Nerim (AS13193), etc.
Ces AS sont interconnectés via des points dits de peering: France-IX, SFINX, PARIX, FreeIX, PanaP, LyonIX, LINX, AMS-IX, DE-CIX, etc. Voir http://en.wikipedia.org/wiki/List_of_Internet_exchange_points.
Par exemple, à quoi est raccordé SFR?
Quelles sont les blocks d’addresse alloués à Free:
whois -r -i org ORG-PISP1-RIPE
À quoi est raccordé Télécom Bretagne? Voyez http://www.robtex.com/dns/telecom-bretagne.eu.html#graph
Un autre concept important est la séparation (conceptuelle) entre cœur et bordure d’Internet. On parle alors de la Default-Free Zone (DFZ). C’est l’ensemble des routeurs qui n’ont pas de route par défaut. Autrement-dit, ce sont les routeurs qui constituent le cœur du réseau Internet (et ceci indépendemment du découpage d’Internet en AS). Par opposition, tous les autres routeurs qui ont à priori une route par défaut vers le reste d’Internet, constituent la la bordure d’Internet.







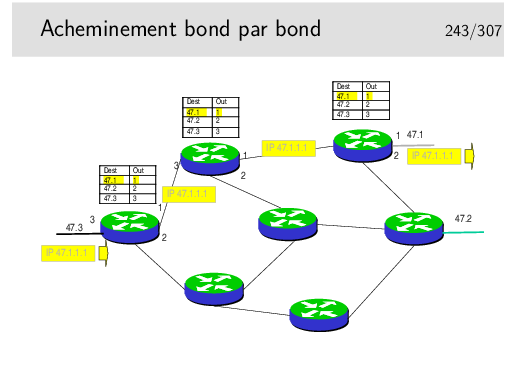
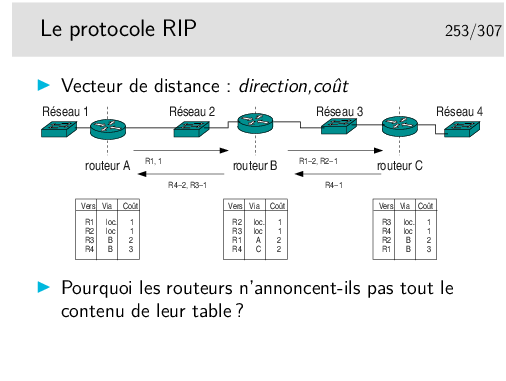
Chaque routeur annonce, systématiquement toutes les 30s, sa table de routage à ses voisins (seulement les réseaux connus et le coût pour les atteindre, ils n’annoncent pas le paramètre «via»). Chaque routeur prend donc «connaissance» de la «connaissance» des ses voisins.
Lorsque l’algorithme a convergé chaque routeur doit connaître l’existence des tous les réseaux. Si une modification du routage apparaît dans un routeur (nouvelle destination, routeur voisin silencieux), le routeur en question recalcule sa table. S’il en résulte une modification (comme dans le cas de l’apparition d’une nouvelle route) il en informe immédiatement ses voisins sans attendre les 30s habituelles.
Le schéma ci-dessus montre les tables pour un réseau simple une fois atteinte la convergence. Pourquoi les routeurs n’annoncent-ils pas toute leur table ? Par exemple, pourquoi A n’annonce-t’il pas R4 ? L’algorithme serait plus simple à implémenter.
En fait A n’annonce pas vers B qu’il connaît R4 car il apprend l’existence de R4 par B lui-même. Et si C tombait en panne, B ne recevant plus d’annonce de C placerait R4 à une distance infinie et le supprimerait de sa table. Puis il indiquerait vers A ce fait nouveau. Mais peut-être que A aurait le temps de communiquer à B sa connaissance de R4 avec un coût de 2. B pourrait alors croire que A connaît une route vers R4.
Cette non annonce, dans une direction, des routes que l’on apprend par elle s’appelle la technique de l’horizon coupé (splitted horizon). Elle n’est pas complètement satisfaisante car s’il existe plusieurs autres routeurs du coté de A et que ceux-ci forment des boucles, il se peut que l’algorithme ne puisse pas converger.

La recherche de chemin n’aboutit pas, des filtrages sur certains routeurs en sont la cause.
Cette commande peut être rapide si on lui ajoute l’option -d qui empêche la traduction des adresses IP en noms.
La commande existe sous Unix/Linux sous le nom traceroute.
La commande ping n’utilise que ICMP (porté par IP).
La commande traceroute (tracert sous Windows) joue sur le dépassement de la durée de vie. Un premier paquet est créé «à la main» et son champ ttl est mis à 1. Il contient un paquet UDP à destination d’un port inconnu. Le paquet est routé, il atteint le premier routeur qui décrémente alors le ttl. Le résultat valant 0 le paquet est jeté et un message ICMP est émis vers la source du paquet jeté. Le message est véhiculé par un paquet IP comportant l’adresse du routeur, ce qu’on attend dans traceroute. On peut alors afficher l’identité de ce routeur ainsi que le temps mesuré entre l’envoi du paquet initial et le l’arrivée du message ICMP. On fait cela trois fois pour avoir une estimation du temps moyen d’aller et retour puis on recommence en mettant cette fois le ttl à 2.




Soyez curieux...
Essayez nslookup sous Windows ou Unix/Linux.
Sous Linux il y a aussi host tout simplement ou dig qui est beaucoup moins simple.
Le DNS peut faire l’objet d’attaques (certaines effectives, d’autres fantasmées...): voir la présentation de Stéphane Bortzmeyer (Afnic) aux journées JCSA 2012 http://www.afnic.fr/fr/l-afnic-en-bref/actualites/actualites-generales/6171/show/succes-pour-la-journee-du-conseil-scientifique-sous-le-signe-de-la-resilience-8.html
Partie IV |

TCP et UDP, deux besoins extrèmes, mais relativement faciles à utiliser. De nombreux protocoles "universitaires" proposent des compromis, des services intermédiaires (p-ex. le protocole POC: Partial Order Connection), mais certains commencent à émerger sérieusement comme DCCP et SCTP.
DCCP: un genre d’UDP mais en mode connecté et avec contrôle de congestion. Pas de préservation de l’ordre des message ni de garantie de transmission des donnée, mais garantie sur les acquittement.
SCTP: un genre de TCP mais orienté flux de messages et non pas flux d’octets (flux: préserve l’ordre et guarantie la transmission); gère le multi-flux au sein d’une même connection, et le multihoming (annoncer que l’on va changer d’adresse IP pour la suite de la session).
MPTCP: compatible avec le TCP classique (programme avec des sockets TCP); définit des nouvelles options pour annoncer des sous-flux, en parallèle ou en secours, rejoindre une autre IP sans clore la session (multihoming), etc.
Ports source et destination: identifient les applications en relation, généralement l’une d’elle est serveur, son port correspond alors au numéro du protocole (exemple: 80 pour les serveurs Web)
Numéro de séquence: numéro du premier octet des données. C’est le rang du premier octet véhiculé par ce segment en comptant depuis le début de l’échange. Le numéro de début est tiré aléatoirement entre 0 et 232-1.
Acquittement: numéro du prochain octet attendu
Offset: indique la longueur de l’entête en mots de 32 bits (si égal à 5 alors pas d’option)
Bits de contrôle (CWR, ECE, Urg, Ack, Psh, Rst, Syn, Fin)
Fenêtre: permet le contrôle de flux, le récepteur indique avec ce champ combien d’octets il est prêt à recevoir (une valeur de 0 indique que ses tampons mémoire sont pleins)
Somme de contrôle: permet de savoir si le segment a été altéré ou non pendant sa transmission
Pointeur de données urgentes: indique l’emplacement de ces données dans le segment (si le bit Urg est positionné, sinon ce champ est ignoré, bien qu’il existe toujours)







Cette option n’est pas une option au sens dans lequel ce mot sera vu plus loin. Il s’agit simplement d’un paramètre interne à l’entité TCP, positionné par l’application à l’aide d’une fonction spécifique (setsockopt(SO_KEEPALIVE)).



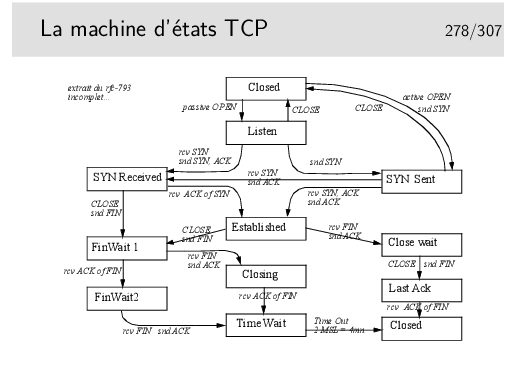
Ces états sont visualisables sous Windows dans une fenêtre de commande avec la commande netstat -p tcp. Sous Linux on fera netstat -at.
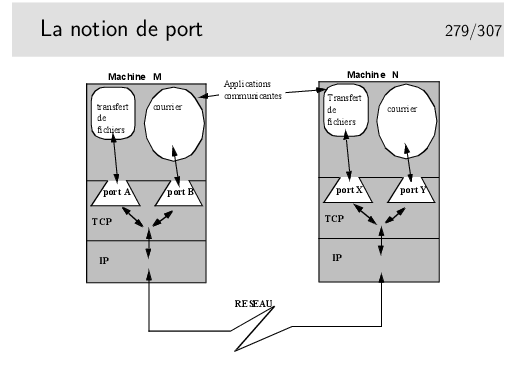
Les ports sont, en quelque sorte, les adresses des applications à l’intérieur des machines. Selon la terminologie OSI, un port est un SAP.
Quelques ports bien connus (voir aussi le fichier /etc/services sous
Unix/Linux, ou C:\WINNT\system32\drivers\etc\services sous Windows)
Pour résumer ce qu’est une «connexion TCP»:

en italique: complément d’information fourni par tcpdump mais ne figurant pas réellement dans le paquet
numéro de séquence du dernier octet, correspondant à l’acquittement alors attendu. Entre parenthèses: nombre d’octets du paquet
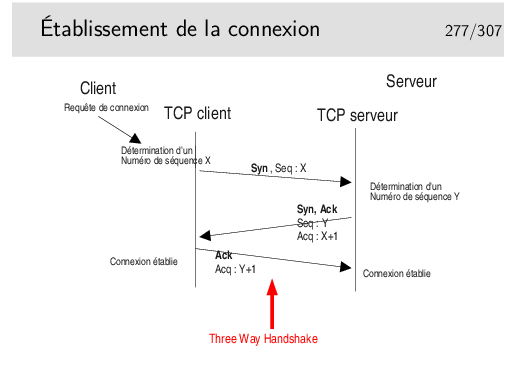
Les trois premières trames correspondent à une ouverture de connexion (Three Way Handshake)

L’option -n de netstat permet de ne pas traduire les adresses et numéros de ports (les services). L’affichage est direct et on ne perd pas de temps en requêtes DNS pour afficher les noms des machines.
L’option -t restreint l’affichage au seul protocole TCP. Avec l’option -u on affiche les services UDP en cours (les applications serveur UDP). Il n’y a pas de connexion en UDP.
Avec la seule option -a on affiche toutes les connexions (ou serveurs lancées pour UDP), y compris les services n’utilisant que la communication Unix (par exemple le serveur d’affichage X-Window local et ses applications clientes).
Voir -p tcp ou -p udp sous Windows

Selon la bibliothèque de développement (sockets sous Unix/Linux ou Windows par exemple) il peut être possible de dimensionner les tampons mémoire d’émission et de réception.
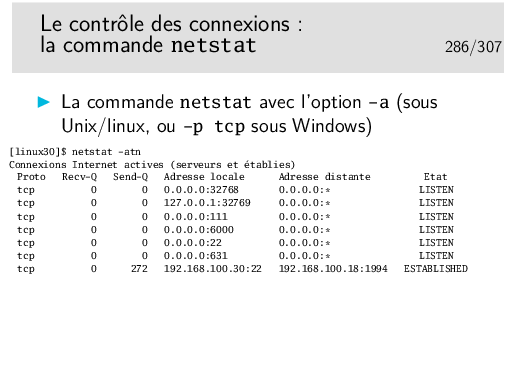
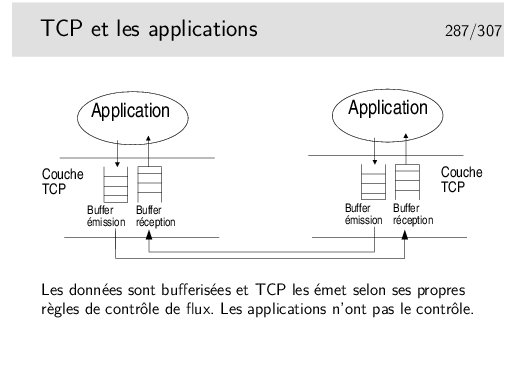
Sur Linux (noyau 2.6.xx), les paramètres liées à la gestion de la taille de
la fenêtre de réception dans la pile TCP sont accessibles par la commande:
$ cat /proc/sys/net/ipv4/tcp_rmem
4096 87380 2076672
Les trois nombres donnent respectivement la valeur minimale (4096 octets), par défaut (87380 octets) et maximale (2076672 octets) de la fenêtre d’une session TCP.


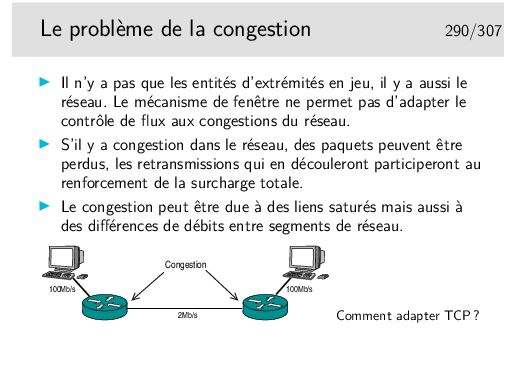
Les valeurs de RTT sont typiquement de:



En italique: ce que tcpdump nous indique concernant la longueur du SDU véhiculé.


UDP n’apporte que peu de choses par rapport à IP. Il garde de TCP la notion de port qui permet d’identifier les applications.
(A noter le champ longueur qui n’existe pas dans TCP)
Il n’y a pas de contrôle de flux, pas d’assurance de remise.
Il n’y a pas de «connexion».
On a cependant l’assurance que, si un datagramme arrive, il correspond très exactement à ce qui a été envoyé en ce qui concerne l’alignement des données. En d’autre termes, on peut dire que UDP est orienté «message». Si un message est reçu, le début correspond au début envoyé, la fin à la fin...
Ce n’est pas vrai en TCP. Lorsqu’une application reçoit un buffer de données via TCP elle ne peut être certaine que cette réception correspond bien à l’émission. Certes les données sont les mêmes, elles ne sont pas alignées. TCP est orienté «flot d’octets», il assure que les octets sont bien transmis.

TCP garantit que les octets sont bien transmis, il ne permet pas l’alignement de la réception sur l’émission. Autrement dit, un premier «message» peut voir son début partir dans un segment TCP et arriver dans un autre. Il faut pouvoir rassembler les octets appartenant à un message donné à l’arrivée. Pour cela on peut utiliser la technique TPKT recommandée dans le RFC 1006 qui consiste à commencer les messages par un octet de version (3), un octet inutilisé (sans doute pour faire joli, ou plus sûrement pour que l’ensemble soit aligné sur 4 octets), et deux octets de longueur de message. En réception il suffit de se synchroniser sur le premier message...
UDP ne garantit pas que les messages arrivent mais s’ils sont reçus, alors, on trouve tout d’un coup (à condition toutefois que la lecture prévoit de de lire un nombre suffisant d’octets).
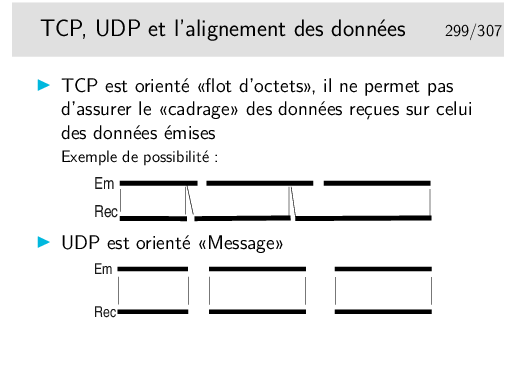
ASN.1: Abstract Notation, version 1 (on espère qu’il n’y aura pas de version 2, ou alors plus simple...): langage de spécification de types de données. Comme un langage informatique ou on ne définirait que des types et des variables de ces types.
On lui associe une syntaxe de transfert (en clair: des mécanismes de codage en ligne) tels que le BER (Basic Encoding Rules) ou le PER (Packet encoding Rules).
ASN.1/BER: utilisé pour snmp (simple network management protocol, rfc 1155 à 1158, 1212, 1213, etc)
ASN.1/PER est utilisé pour définir les données de signalisation pour la téléphonie sur IP dans l’architecture H323 (définition des PDUs H225 et H245, plusieurs centaines de pages, avec rien que du ASN.1 goûteux et savoureux).
On retrouve aussi ASN.1 dans les spécifications de la structure des certificats de sécurité X509.


Coté client, c’est au programmeur de l’application de préparer «à la main» les chaînes de caractères constituant les messages de requêtes du protocole. Coté serveur il faut savoir interpréter ces messages (le mot «savoir» étant traduisible en «implémentation de code»), il faut savoir aussi constituer les messages de réponse. Ces messages sont donc des suites de caractères ascii, placés dans des tampons mémoire qu’il suffit ensuite d’envoyer sur des sockets, coté émission. Coté réception il suffit de lire les sockets (comme on lirait des fichiers) et d’analyser en,suite ce qui est mémorisé dans les tampons de lecture.
Le langage est simple, il obéit à une grammaire (au sens informatique du terme) parfaitement spécifiée. Il est possible, à partir des spécifications de générer facilement des fonctions de traitement des messages. Il existe des outils adaptés aux traitements lexicaux, voire sémantiques, de telles grammaires: lex et yacc sous unix, flex et bison en logiciels libres.
S: indique l’émetteur, R: indique le récepteur. (S: et R: ne font pas partie du protocole.)
MAIL FROM:, RCPT TO:, DATA sont des entêtes du protocole, de même que les séquences <CRLF> qui signifient simplement retour à la ligne pour CR (Carriage Return) et saute de ligne pour LF (Line Feed).
On peut noter que le cacatère . (point) est aussi partie intégrante du protocole.
Voici donc le protocole de base du courrier Internet si utilisé aujourd’hui. Ses spécification datent d’août 1982 !
Que pensez-vous des aspects sécurité d’un tel protocole ?

POP: Post Office Protocol
IMAP: Internet Message Access Protocol
Les protocoles POP et IMAP sont par défaut sans chiffrement et nécessitent l’échange de mots de passe utilisateur. Ces échanges se font par défaut en clair pour POP. IMAP supporte différents mécanismes d’authentification, notemment un système de challange dans lequel le mot de passe est chiffré (pour autant, les messages ne le sont pas...) Les outils clients ainsi que les serveurs peuvent être configurés pour fonctionner avec chiffrement (POPS ou IMAPS: POP/IMAP + SSL).
POP permet de télécharger sur son poste client les courriers reçus sur le serveur final. Les messages sont totalement transférés. Ils peuvent cependant rester sur le serveur.
IMAP permet de ne charger que les entêtes, il permet aussi de rechercher les messages par mot clé, les messages peuvent rester stockés sur le serveur, et de gérer des sous-répertoires (folders) sur le serveur.

Il peut y avoir plus de machines intermédiaires que ne le montre la figure ci-dessus. En particulier, coté réception, la machine serveur (appelée ici postoffice.firme.com) peut renvoyer vers un serveur interne déservant le département de l’utilisateur joe, ce denier paramètre alors son client pour qu’il se connecte par POP ou IMAP sur ce serveur particulier.
Il peut y avoir plusieurs serveurs d’arrivée, classés selon des priorités dans le DNS.
Il peut être intéressant de regarder l’entête complète des messages que l’on reçoit pour avoir la liste des MTA traversées par ces messages. Cette curiosité étant encore plus intéressante en cas de problèmes d’acheminement.
Les MTAs peuvent filtrer les messages, au départ comme à l’arrivée. Ils peuvent être munis de détecteurs de SPAMs et de virus.
Vous pouvez tester le DNS avec des requêtes MX de la manière suivante (sous Windows):
c:\nslookup > set type=MX > microsoft.com
Ou sous Unix: host -t MX microsoft.com (la commande nslookup, bien qu’encore présente, est maintenant considérée comme rendue obsolète par la commande host).
Ce document a été traduit de LATEX par HEVEA